

Lead scoring is a methodology used by sales and marketing departments to determine the worthiness of leads, or potential customers, by attaching values to them based on their behavior relating to their interest in products or services. Here’s a step-by-step guide on how to build a lead scoring model using PyCaret and increase the ROI on marketing campaigns.
This article was originally published by PyCaret.
Introduction
Leads are the driving force of many businesses today. With the advancement of subscription-based business models particularly in the start-up space, the ability to convert leads into paying customers is key to survival. In simple terms, a “lead” represents a potential customer interested in buying your product/service.Normally when you acquire the lead, either through a third party service or by running a marketing campaign yourself, it typically includes information like:
- Name and contact details of the lead
- Lead attributes (demographic, social, customer preferences)
- Source of origin (Facebook Ad, Website landing page, third party, etc.)
- Time spent on the website, number of clicks, etc.
- Referral details, etc.
Lead Management Process at a Glance
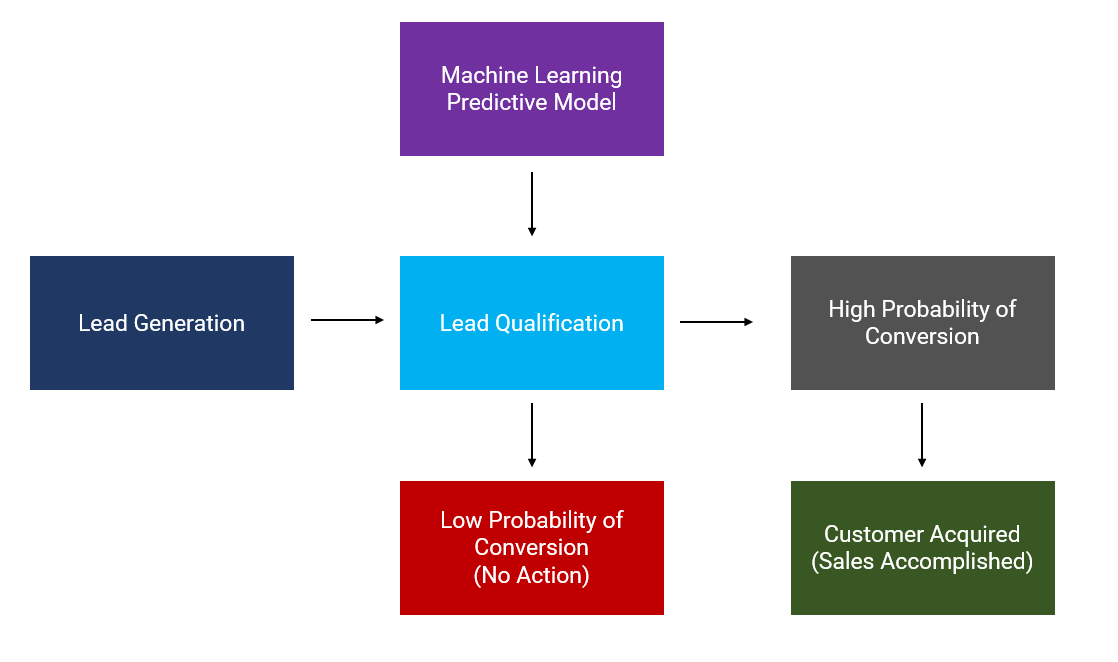
A significant amount of time, money, and effort is spent by marketing and sales departments on lead management, a concept that we will take to encompass the three key phases of lead generation, qualification, and monetization.
👉Lead Generation
Lead generation is the initiation of customer interest or inquiry into the products or services of your business. Leads are created with the intent of converting the interest or inquiry into sales. There is an unlimited number of third-party companies on the internet that promises to generate the best leads. However, you can also do it yourself by running marketing campaigns. The methods for generating leads typically fall under the umbrella of advertising, but may also include non-paid sources such as organic search engine results or referrals from existing customers.
👉 Lead Qualification
Lead qualification refers to the process of determining which potential customers are most likely to make an actual purchase. It’s an integral part of the sales funnel, which often takes in many leads but only converts a fraction of them. Lead qualification in simple terms means assessing and prioritizing the leads to come up with the likelihood of conversion so that your marketing and sales department can chase the prioritized leads instead of all the leads which can often by in thousands.
👉Lead Conversion
Lead conversion is a phase where you finally convert a qualified lead into paying customer. It entails all the marketing practices that stimulate a desire to buy a product or service and push a lead towards a purchasing decision*. *This is a monetization or closing phase and the outcome of this generally defines the success of the overall marketing campaign.
👉 What does Lead Scoring Really Mean?
Imagine your team has many leads (potential customers) but not enough resources to pursue them all. Whether you are a product-led business with tons of freemium users, have a great inbound funnel of leads, or simply an amazing door-to-door sales team, at the end of the day, you need to prioritize the time of your sales teams and give them the “best” leads.
The question is how do you do it so you maximize your win rate?
One simple way of doing this is by analyzing the historic data and look at attributes based on which the leads have converted into sales. For example, there could be a particular country, city, or postal code where leads have converted to sales 90% of the time historically. Similarly, your data can also tell you customers who have spent more than 20 minutes on your website are converted into sales most of the time. Using these business rules you can create a **Lead Scoring System **that attaches scores (higher the better) to each lead using these business rules.The problem with this approach is, there is only so much you can cover with business rules. As your business expands, the type and variety of data you can collect will grow exponentially. At some point, a manual rule-based system will not be robust enough to continue to add value.
Here comes Machine Learning
You can approach the **Leading Scoring System **from a machine learning perspective, where you can train ML models on customer attributes, lead origin, referrals, and other details available and the target will be Lead Converted (Yes or No).
How do you get the target variable? Well, most CRM systems like Salesforce, Zoho, or Microsoft Dynamics can track the individual lead and their status. The status of the lead will help you create the target variable.
One word of caution is you have to make sure that you do not leak any information in the training dataset. For example, your CRM system could store the information regarding referral paid to third-party on lead conversion, imagine if you use that information in your training data, it is technically a leakage as you will only pay a referral fee on conversion, and this is something you know after the fact.
Let’s get started with the practical example 👇
What is PyCaret?
PyCaret is an open-source, low-code machine learning library and end-to-end model management tool in Python to automate machine learning workflows. Using PyCaret you can efficiently build and deploy end-to-end machine learning pipelines. To learn more about PyCaret, check out their GitHub.
Install PyCaret
**# install pycaret
**pip install pycaret👉Dataset
For this tutorial, I am using a Lead Conversion dataset from Kaggle. The dataset contains over 9,000 leads with customer features such as lead origin, source of lead, total time spent on the website, total visits on the website, demographics information, and the target column Converted (indicating 1 for conversion and 0 for no conversion).
**# import libraries**
import pandas as pd
import numpy as np
**# read csv data
**data **= **pd.read_csv('[Leads.csv'](https://raw.githubusercontent.com/srees1988/predict-churn-py/main/customer_churn_data.csv'))
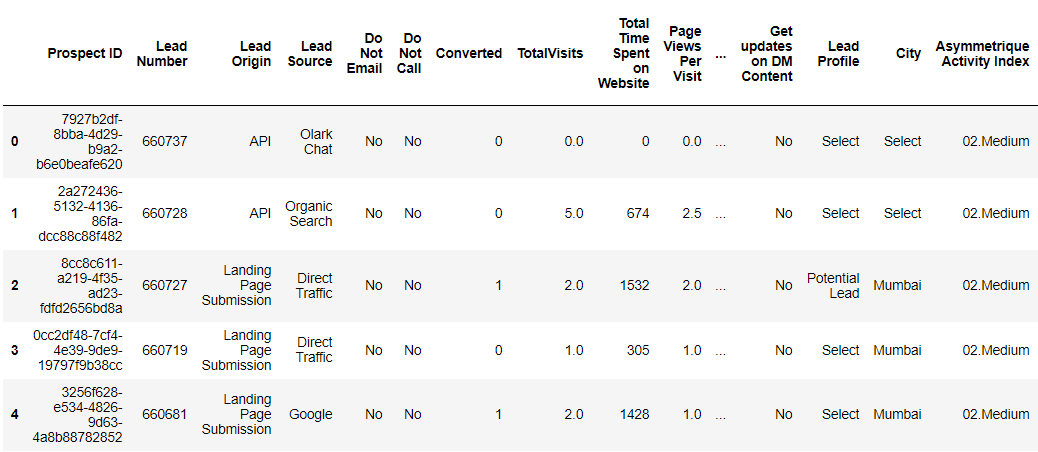
data.head()
👉 Exploratory Data Analysis
**# check data info **data.info()
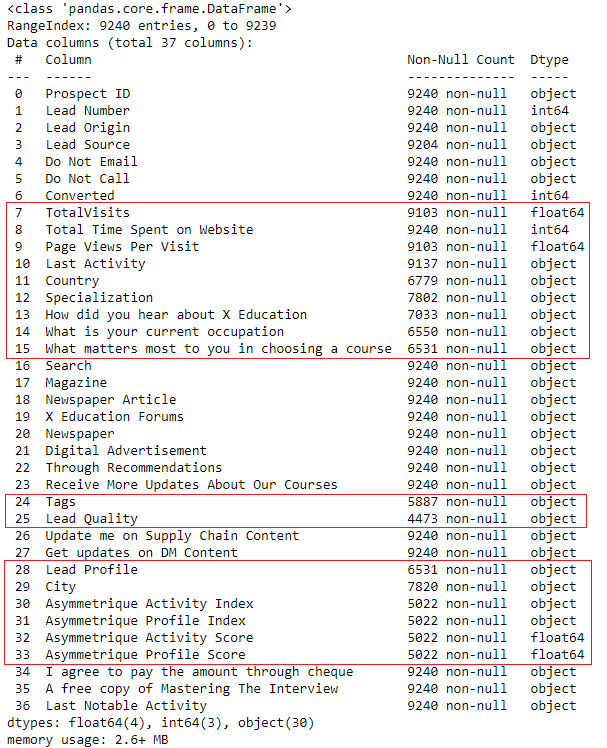
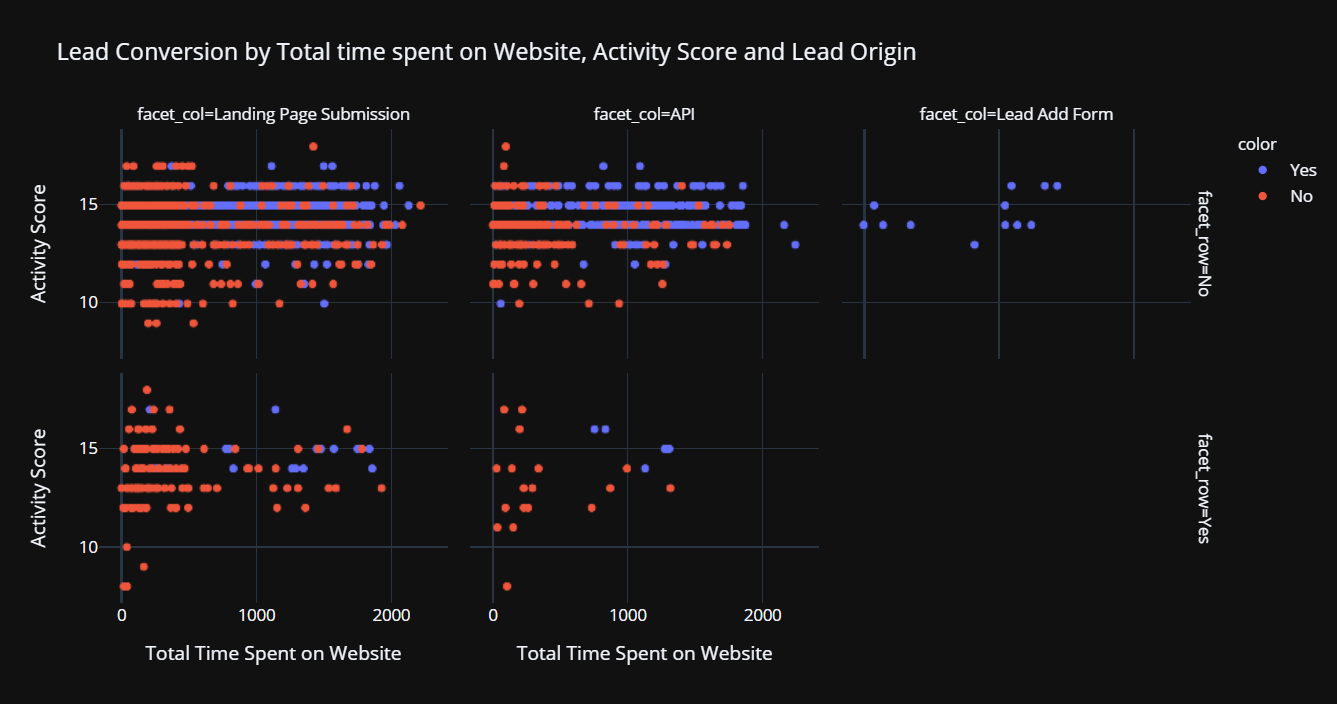
Notice that there are several columns that have many missing values. There are several ways to deal with missing values. I will leave it for PyCaret to automatically handle the missing values. If you would like to learn more about different methods of imputing missing values in PyCaret, check out this documentation link. Intuitively time spent on the website and the activity score along with the source of lead are very important information when it comes to lead conversion. Let’s explore the relationship visually:
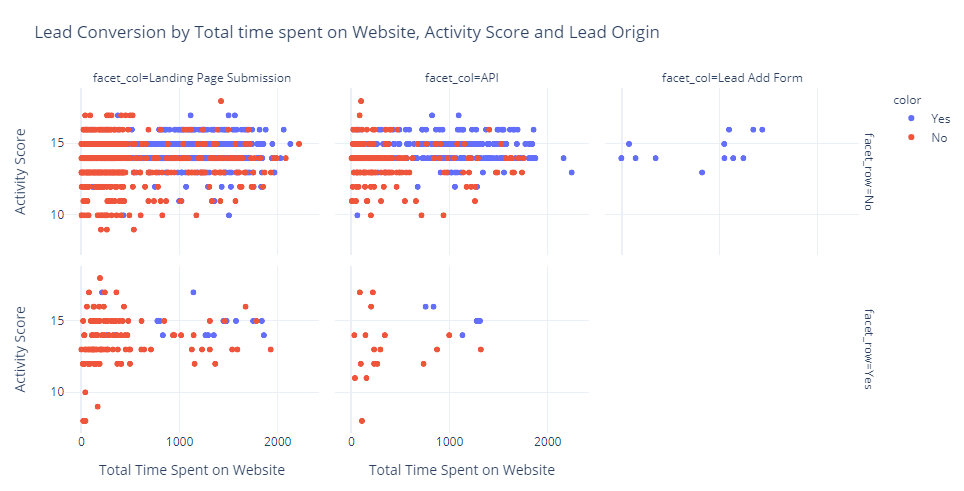
Notice that leads coming from the “Add Forms” are likely to convert into sales irrespective of the time spent on the website or the score. For lead originated through API or landing page of the website tells a different story. A higher score along with higher time spent on the website is more likely to convert leads into final sales.
👉Data Preparation
Common to all modules in PyCaret, the setup is the first and the only mandatory step in any machine learning experiment performed in PyCaret. This function takes care of all the data preparation required prior to training models. Besides performing some basic default processing tasks, PyCaret also offers a wide array of pre-processing features. To learn more about all the preprocessing functionalities in PyCaret, you can see this link.
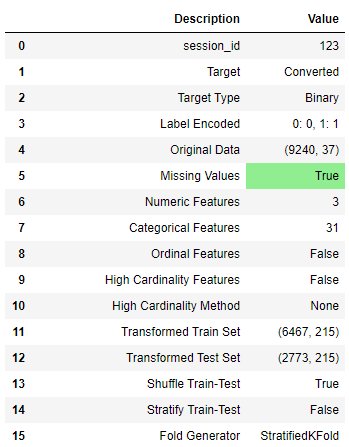
**# init setup** from pycaret.classification import * s = setup(data, target = 'Converted', ignore_features = ['Prospect ID', 'Lead Number'])
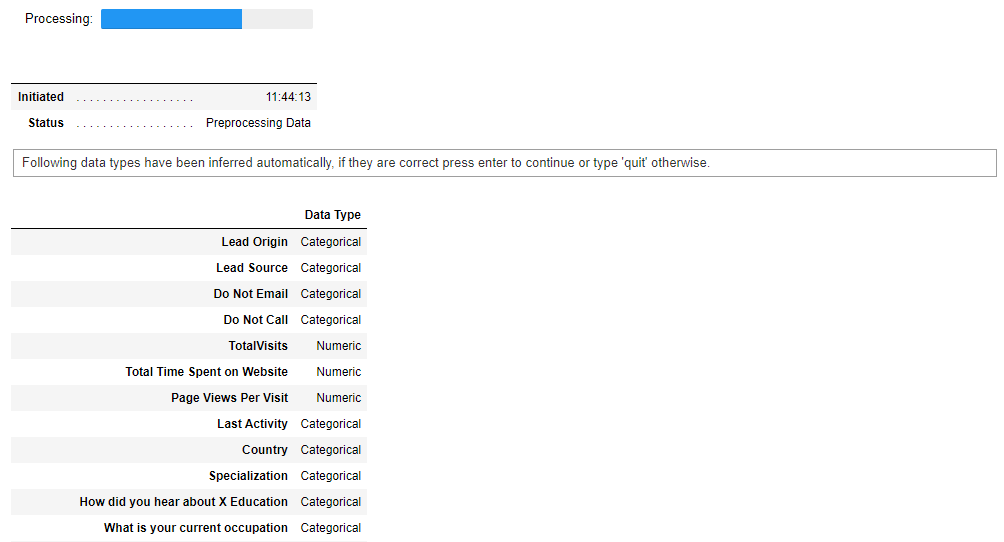
Upon initializing the setup function in PyCaret, it automatically profiles the dataset and infers the data types for all input variables. If everything is inferred correctly you can press enter to continue. You can also use numeric_features and categorical_features parameter in the setup to force/overwrite the data types.Also, notice that I have passed ignore_features = [‘Prospect ID’, ‘Lead Number’] in the setup function so that it is not considered when training the models. The good thing about this is PyCaret will not remove the column from the dataset, it will just ignore it behind the scene for model training. As such when you generate predictions at the end, you don’t need to worry about joining IDs back by yourself.
👉 Model Training & Selection
Now that data preparation is done, let’s start the training process by using compare_models functionality. This function trains all the algorithms available in the model library and evaluates multiple performance metrics using cross-validation.
**# compare all models** best_model = compare_models(sort='AUC')
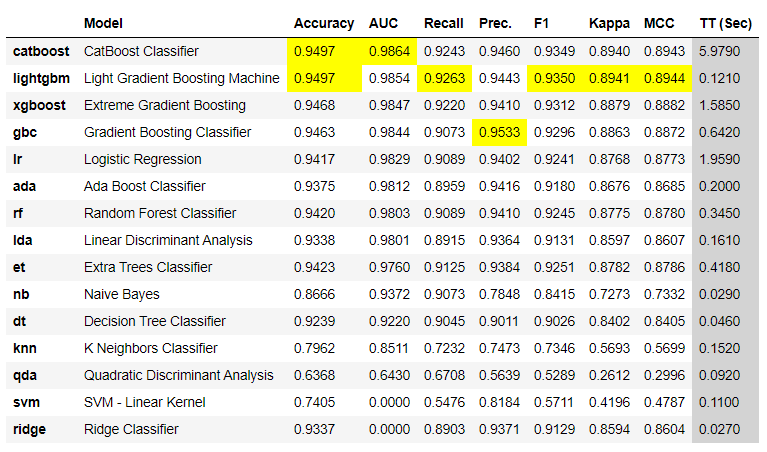
The best model based on AUC* *is Catboost Classifier with an average 10 fold cross-validated AUC of 0.9864.
**# print best_model parameters** print(best_model.get_all_params()) **# except for catboost you can do this:** print(best_model)
👉 Model Analysis
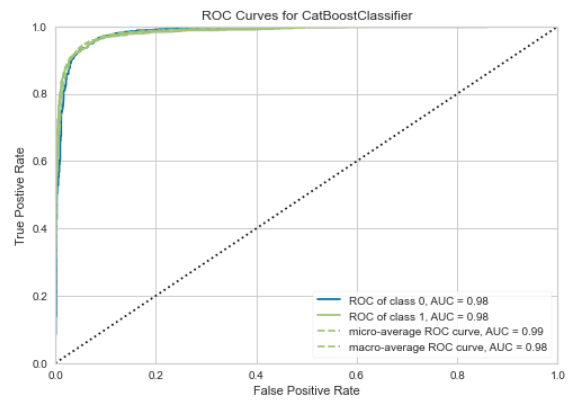
AUC-ROC Plot
AUC — ROC curve is a performance measurement for the classification problems at various threshold settings. ROC is a probability curve and AUC represents the degree or measure of separability. It tells how much the model is capable of distinguishing between classes. The higher the AUC, the better the model is at predicting positive and negative classes. While it is very helpful to assess and compare the performance of different models, it is not easy to translate this metric into business value.
**# AUC Plot** plot_model(best_model, plot = 'auc')
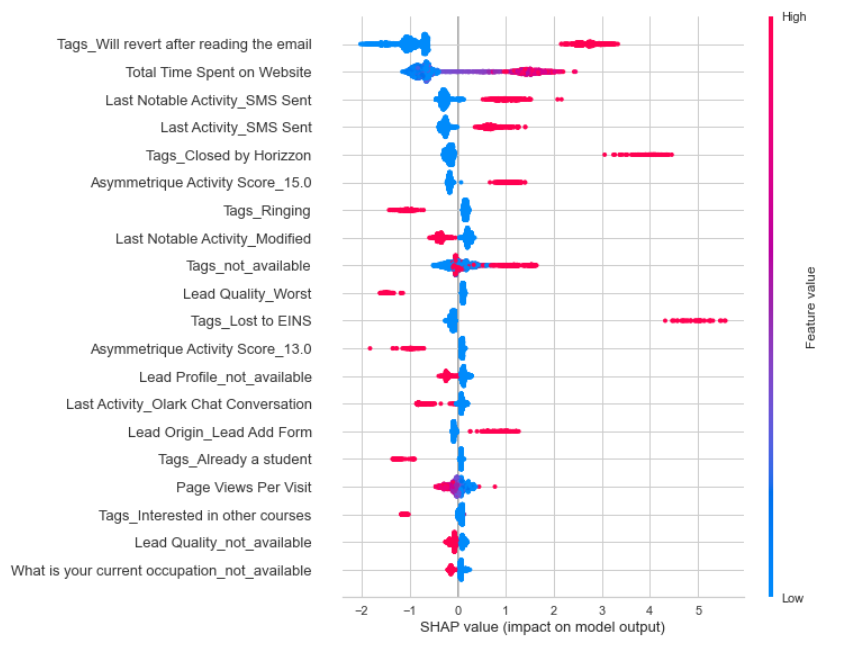
SHAP Values
Unlike AUC-ROC, shap values do not tell you anything about model performance but instead, interpret the impact of having a certain value for a given feature in comparison to the prediction we’d make if that feature took some baseline value. In the chart below, the y-axis (left) has all the important features of the model, the x-axis is the Shapley value of associated features and the color scale (on right) is the actual value of the feature. Each dot on a graph at each feature is a customer lead (from the test set) — overlapping each other.The higher the shap value is (x-axis), the higher the likelihood of positive class (which in this case is conversion). So reading from the top, I will interpret this as leads that are tagged as “will revert after reading the email” has a high shap value compared to the base meaning a higher likelihood of conversion. On the contrary, if you see the tag “Ringing”, is exactly the opposite where shap values are on the left side of the base value i.e. negative shap values meaning that this feature is working against conversion. To get a more detailed understanding of shap values, see this link.
**# Shapley Values** interpret_model(best_model)
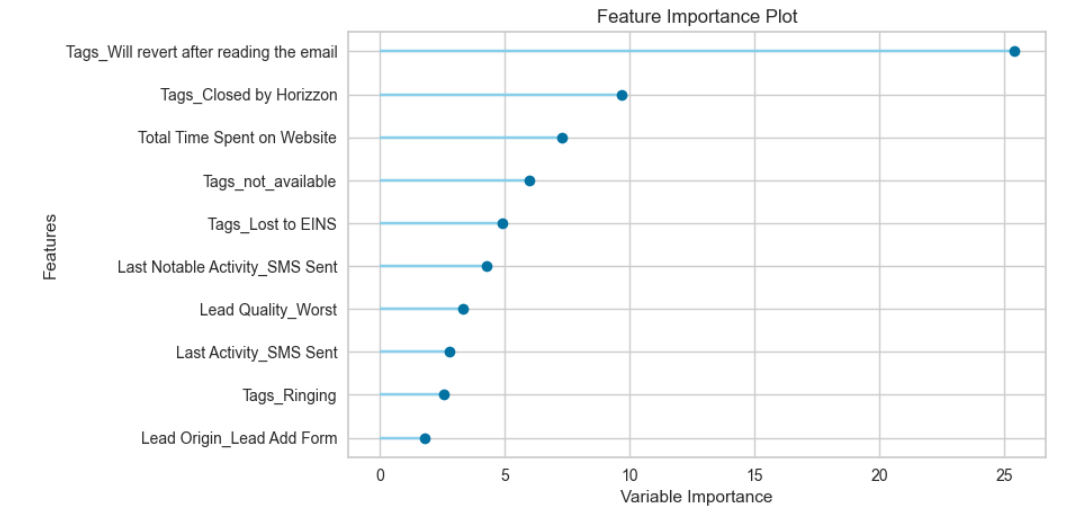
Feature Importance Plot
A feature importance plot is just another way to interpret model results. While Shap values only work for complex tree-based model, feature importance plot is more common and can be used for different families of models. Unlike shap values, feature importance does not tell us the impact of the feature on a particular class, it only tells us if the feature is important
**# Feature Importance **plot_model(best_model, plot = 'feature')
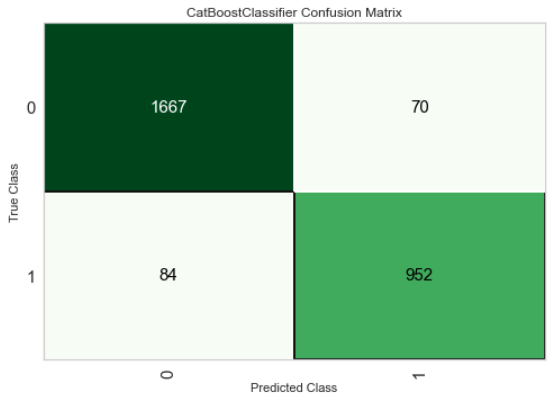
Confusion Matrix
The confusion matrix is another way to look at model performance. Out of all the possible tools, this is perhaps the simplest one. It basically compared the predictions with actual labels and divide them into four quadrants:
- True Positive (Prediction: Conversion, Actual: Conversion)
- True Negative (Prediction: No Conversion, Actual: No Conversion)
- False Positive (**Prediction: **Conversion, Actual: No Conversion)
- False Negative (Prediction: No Conversion, Actual: Conversion)
If you sum up all the four quadrants, it will equal the number of customer leads in the test set (1667 + 70 + 84 + 952 = 2,773).
- 952 customers (bottom right quadrant) are true positives, these are the leads model predicted will convert and they converted;
- 70 leads are false positive (this is where you might have spent efforts that will go to waste);
- 84 leads are false negatives i.e. (missed opportunities); and
- 1,667 leads are true negatives (no impact).**# Confusion Matrix **plot_model(best_model, plot = ‘confusion_matrix’)
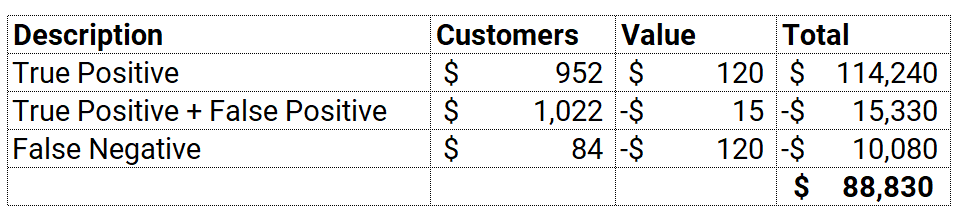
So far we have prepared the data for modeling (PyCaret does that automatically when you run the setup function), trained multiple models to select the best model based on the AUC, analyzed performance via different plots such as AUC-ROC, Feature Importance, Confusion Matrix, and Shapley values. However, we haven’t answered the most important question yet:
What’s the business value of this model and why should we use this model?
In order to attach business value to this model, let us make few assumptions:
- Lead converted into sales will yield $120 in Revenue for the first year
- Time and efforts spent on chasing prioritized leads (as predicted by the model) is $15
- Opportunities missed by the model (False negatives) yield negative $120 as opportunity cost (you may or may not add this as this is not the real cost but an opportunity cost, — totally depends on the use case)
If you just do a little maths here, you will arrive at $88,830 in profit. Here’s how:
This may be a good model but it is not a business-smart model as we haven’t fed in the assumptions of cost/profit yet. By default, any machine learning algorithm will optimize conventional metrics like AUC. In order to achieve the business goal, we have to train, select, and optimize models using business metrics.
👉 Adding Custom Metric in PyCaret
Thanks to PyCaret, it is extremely easy to achieve this using add_metric function.
**# create a custom function
**def calculate_profit(y, y_pred):
tp = np.where((y_pred==1) & (y==1), (120-15), 0)
fp = np.where((y_pred==1) & (y==0), -15, 0)
fn = np.where((y_pred==0) & (y==1), -120, 0)
return np.sum([tp,fp,fn])
**# add metric to PyCaret
**add_metric('profit', 'Profit', calculate_profit)
Now let’s run compare_models again:
**# compare all models** best_model = compare_models(sort='Profit')
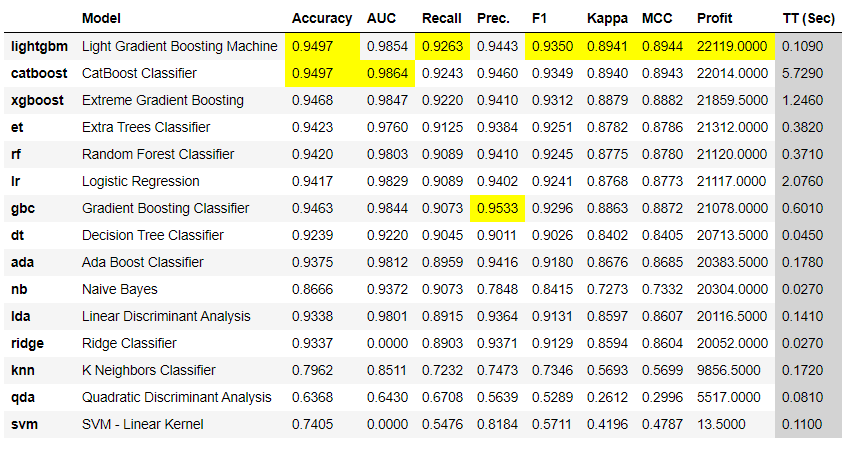
Notice that a new column Profit is added this time and **Catboost Classifier **is no more the best model based on Profit. It is **Light Gradient Boosting Machine. **Although the difference is not material in this example but depending on your data and assumptions, this could be millions of dollars sometimes.
**# confusion matrix** plot_model(best_model, plot = 'confusion_matrix')
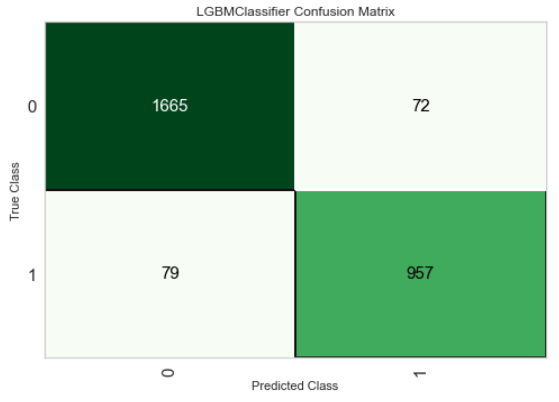
The total number of customers is still the same (2,773 customers in the test set), what’s changed is now how the model is making errors over false positives and false negatives. Let’s put some $ value against it, using the same assumptions (as above):
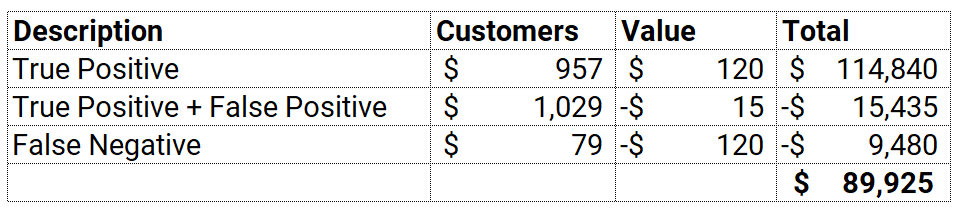
The profit is now $89,925 compared to $88,830 when Catboost Classifier was used. This is a 1.2% lift which depending on the magnitude and cost of false positive and false negative could translate into millions of dollars. There are few other things you can do on top of this such as tune hyperparameters of your best model by explicitly optimizing Profit instead of AUC, Accuracy, Recall, Precision, or any other conventional metric.
How to Use the Model to Generate a Lead Score?
Well, you must be asking now that we have selected the best model, how do I apply this model to new leads to generate the score? Well, that ain’t hard.
**# create copy of data
**data_new = data.copy()
data_new.drop('Converted', axis=1, inplace=True)
**# generate labels using predict_model
**predict_model(best_model, data=data_new, raw_score=True)
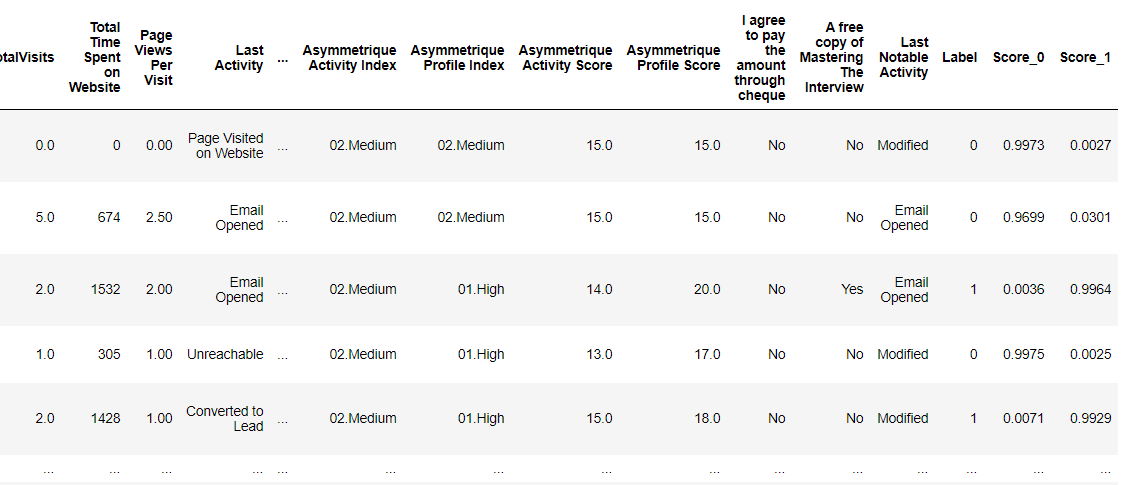
Notice the last three columns are added to the dataset — Label (1 = conversion, 0 = no conversion), Score_0, and Score_1 is the probability for each class between 0 to 1. For example, the first observation Score_0 is 0.9973 meaning 99.7% probability for no conversion.
