

Enterprise business processes are increasingly getting complex. As a result, existing data pipelining approaches, based on traditional ETL, are becoming expensive and cumbersome. Here is a smarter and agile way to build data pipelines, based on business entities – “entity-based ETL” (eETL).
This article was originally posted in K2View.
Data Pipelining in Traditional ETL
The traditional approach to data integration, known as extract-transform-load (ETL), has been around since the 1970s. In the ETL process, data is extracted in bulk from various sources, transformed into a desired format, then loaded for storage into its target destination.
ETL workflow
| Extract | Transform | Load |
|---|---|---|
| Raw data is read and collected from various sources, including message queues, databases, flat files, spreadsheets, data streams, and event streams. | Business rules are applied to clean the data, enrich it, anonymize it, if necessary, and format it for analysis. | The transformed data is loaded into a big data store, such as a data warehouse, data lake, or non-relational database. |
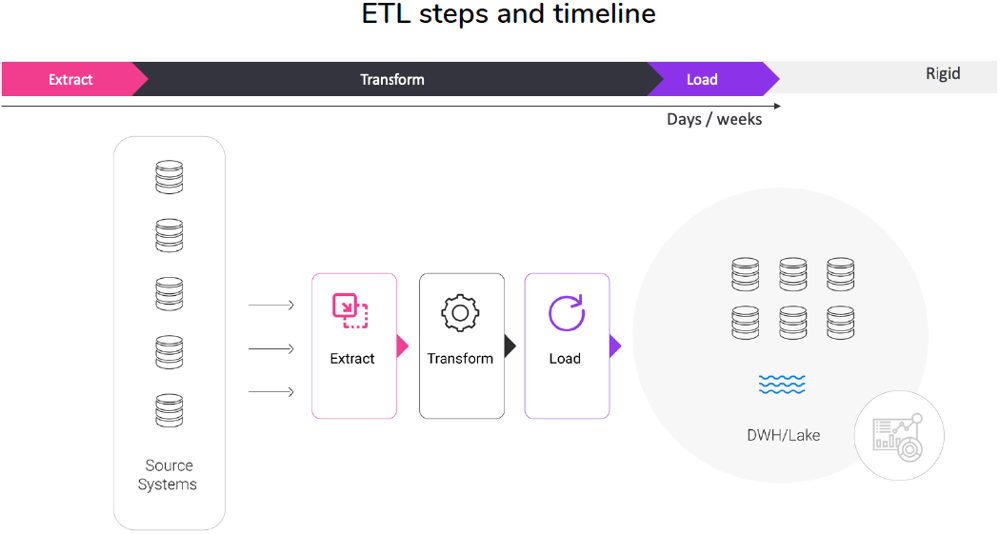
Traditional ETL has the following disadvantages:
Smaller extractions: Heavy processing of data transformations (e.g., I/O and CPU processing of high-volume data) often means having to compromise on smaller data extractions.
Complexity: Traditional ETL is comprised of custom-coded programs and scripts, based on the specific needs of specific transformations. This means that the data engineering team must develop highly specialized, and often non-transferrable, skill sets for managing its code base.
Cost and time consumption: Once set up, adjusting the ETL process can be both costly and time consuming, often requiring lengthy re-engineering cycles – by highly skilled data engineers.
Rigidity: Traditional ETL limits the agility of data scientists, who receive only the data after it was transformed and prepared by the data engineers – as opposed to the entire pool of raw data – to work with.
Legacy technology: Traditional ETL was primarily designed for periodic, batch migrations, was performed on-premise and does not support continuous data streaming. It is also extremely limited when it comes to real-time data processing, ingestion, or integration.
ELT over ETL: Pros and Cons
ELT stands for Extract-Load-Transform. Unlike traditional ETL, ELT extracts and loads the data into the target first, where it runs transformations, often using proprietary scripting. The target is most commonly a data lake, or big data store, such as Teradata, Spark, or Hadoop.
ELT has several advantages over ETL, such as:
- Fast extraction and loading: Data is delivered into the target system immediately, with very little processing in-flight.
- Lower upfront development costs: ELT tools are good at moving source data into target systems with minimal user intervention, since user-defined transformations are not required.
- Low maintenance: ELT was designed for use in the cloud, so things like schema changes can be fully automated.
- Greater flexibility: Data analysts no longer have to determine what insights and data types they need in advance, but can perform transformations on the data as needed in the data warehouse or lake.
- Greater trust: All the data, in its raw format, is available for exploration and analysis. No data is lost, or mis-transformed along the way.
While the ability to transform data in the data store answers ELT’s volume and scale limitations, it does not address the issue of data transformation, which can be very costly and time-consuming. Data scientists, who are high-value company resources, need to match, clean, and transform the data – accounting for 40% of their time – before even getting into any analytics.
ELT is not without its challenges:
- Costly and time consuming: Data scientists need to match, clean, and transform the data before applying analytics.
- Compliance risks: ELT tools don’t have built-in support for data anonymization (while ensuring referential integrity) and data governance, thereby introducing data privacy risks.
- Data migration costs and risks: The movement of massive amounts of data, from on-premise to cloud environments, consumes high network bandwidth.
- Big store requirement: ELT tools require a modern data staging technology, such as a data lake, where the data is loaded. Data teams then transform the data into a data warehouse where it can be sliced and diced for reporting and analysis.
- Limited connectivity: ELT tools lacks connectors to legacy and on-premise systems, although this is becoming less of an issue as ELT products mature, and legacy systems are retired.
Smaller extractions: Heavy processing of data transformations (e.g., I/O and CPU processing of high-volume data)often means having to compromise on smaller data extractions.
Complexity: Traditional ETL is comprised of custom-coded programs and scripts, based on the specific needs of specific transformations. This means that the data engineering team must develop highly specialized, and often.
ETL vs ELT
The following table summarizes the main differences between ETL vs ELT:
| ETL | ELT | |
| Process | 1. Data is extracted in bulks from sources, transformed, then loaded into a DWH/lake. 2. Typically batch | 1. Raw data is extracted and loaded directly into a DWH/lake, where it is transformed 2. Typically batch |
| Primary Use | 1. Smaller sets of structured data that require complex data transformation 2. Offline, analytical workloads | 1. Massive sets of structured and unstructured data 2. Offline, analytical workloads |
| Flexibility | 1. Rigid, requiring data pipelines to be scripted, tested, and deployed 2. Difficult to adapt, costly to maintain | 1. Data scientists and analysts have access to all the raw data. 2. Data is prepared for analytics when needed, using self-service tools |
| Time to insights | 1. Slow – data engineers spend a lot of time building data pipelines | 1. Slow – data scientists and analysts spend a lot of time preparing the data for analytics |
| Compliance | 1. ETL anonymizes confidential and sensitive information before loading it to the target data store | 1. With raw data loaded directly into the big data stores, there are greater chances of accidental data exposure and breaches |
| Technology | 1. Mature and stable, used for 20+ years 2. Supported by many tools | 1. Comparatively new, with fewer data connectors, and less advanced transformation capabilities 2. Supported by fewer professionals and tools |
| Bandwidth and computation costs | 1. Can be costly due to lengthy, high-scale, and complex data processing 2. High bandwidth costs for large data loads 3. Can impact source systems when extracting large data sets | 1. Can be very costly due to cloud-native data transformations 2. Typically requires staging area 3. High bandwidth costs for large data loads |
A New Approach: Entity-Based ETL (eETL)
An innovative new approach addresses the limitations of both traditional ETL and ELT, and delivers trusted, clean, and complete data that can immediately be used to generate insights.
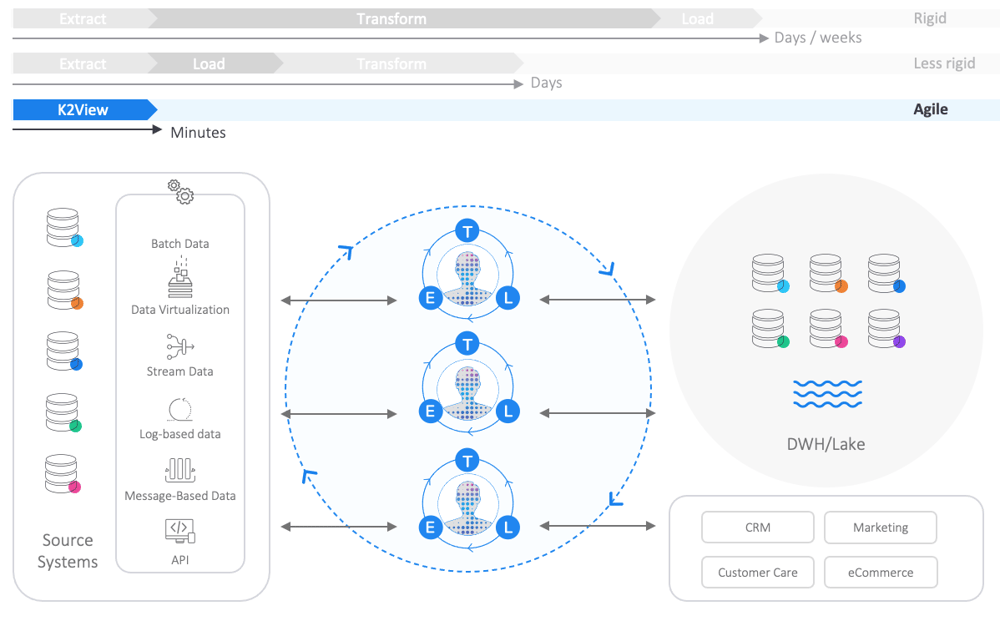
At the foundation of the eETL approach is a logical abstraction layer that captures all the attributes of any given business entity (such as a customer, product or order), from all source systems. Accordingly, data is collected, processed, and delivered per business entity (instance) as a complete, clean, and connected data asset.
In the extract phase, the data for a particular entity is collected from all source systems.
In the transform phase, the data is cleansed, enriched, anonymized, and transformed – as an entity – according to predefined rules.
In the load phase, the entity data is safely delivered to any big data store.
The Best of Both Worlds
eETL represents the best of both (ETL and ELT) worlds, because the data in the target store is:
Extracted, transformed, and loaded – from all sources, to any data store, at any scale – via any data integration method: messaging, CDC, streaming, virtualization, JDBC, and APIs
Always clean, fresh, and analytics-ready
Built, packaged and reused by data engineers, for invoking by business analysts and data scientists
Continuously enriched and connected, to support complex queries and avoid the need for running heavy processing table joins
ETL vs ELT vs eETL
The table below summarizes the ETL vs ELT vs eETL approaches to big data preparation:
| ETL | ELT | eETL | |
|---|---|---|---|
| Process | Data is extracted in bulks from sources, transformed, then loaded into a DWH/lake Typically batch | Raw data is extracted and loaded directly into a DWH/lake, where it is transformed Typically batch | ETL is multi-threaded by business entitiesData is clean, fresh, and complete by design Batch or real time |
| Primary Use | Smaller sets of structured data that require complex data transformation Offline, analytical workloads | Massive sets of structured and unstructured data Offline, analytical workloads | Massive amounts of structured and unstructured data, with low impact on sources and destinations Complex data transformation is performed in real time at the entity level, leveraging a 360-degree view of the entity Operational and analytical workloads |
| Flexibility | Rigid, requiring data pipelines to be scripted, tested, and deployed Difficult to adapt, costly to maintain | Data scientists and analysts have access to all the raw data Data is prepared for analytics when needed, using self-service tools | Highly flexible, easy to set up and adapt Data engineers define the entity data flows Data scientists decide on scope, time and destination of data |
| Time to insights | Slow – data engineers spend a lot of time building data pipelines | Slow – data scientists and analysts spend a lot of time preparing the data for analytics | Quick – data preparation is done instantly and continuously, in real time |
| Compliance | ETL anonymizes confidential and sensitive information before loading it to the target data store | With raw data loaded directly into the big data stores, there are greater chances of accidental data exposure and breaches | Data is anonymized and is fully compatible with privacy regulations (GDPR, CCPA) before loading it to the target data store |
| Technology | Mature and stable, used for 20+ years Supported by many tools | Comparatively new, with fewer data connectors, and less advanced transformations Supported by fewer professionals and tools | Mature and stable, used for 12+ years Proven at very large enterprises, at massive scale |
| Bandwidth and computation costs | Can be costly due to lengthy, high-scale, and complex data processing High bandwidth costs for large data loads Can impact source systems when extracting large data sets | Can be very costly due to cloud-native data transformations Typically requires staging area High bandwidth costs for large data loads | Low computing costs since transformation is done per digital entity, on commodity hardware No data staging Bandwidth costs are reduced by 90% due to smart data compression |
The best method for you
As explained above in the ETL vs ELT comparison, each data pipeline method has its own advantages and disadvantages.
Applying an entity-based approach to data pipelining enables you to overcome the limitations of both approaches and deliver clean and ready-to-use data, at high scale, without having to compromise on flexibility, data security, and privacy compliance requirements.
