
Organizations are always on the lookout for ways to improve their customer support. Providing answers to the customer’s questions in a faster and more accurate way is at the core of that. A standard tool to help customers find required information is a Frequently Asked Questions (FAQ) webpage. However, the FAQ page does not necessarily address all the questions that a customer has. As more and more products or services get added to an organization’s portfolio, it becomes difficult to keep a general FAQ page updated.
This post was originally published in PubNub
In this tutorial, we’ll showcase how Watson Discovery and PubNub work together to intelligently search a wide variety of data types and formats. We’ll build an FAQ bot that answers customer questions by querying existing product documentation.
And to sweeten the pot, we’ll show the answers in different languages based on the customer’s choice (thanks to Watson again).
Introduction to Watson Discovery
Watson Discovery Service is a set of APIs to store, assimilate and enrich your data to extract information at scale. With the help of advanced machine learning and deep learning techniques, the discovery service helps you understand hidden insights in your data quickly.
The service is designed to enable deep dive into the data, either structured or unstructured, monitor trends, gain valuable meaning and context to use and make your system smarter. With the ability to query data in natural language, the discovery service provides a way to augment your application with a conversational interface.
Like all cognitive services, you also have the option to custom train the discovery service for your specific use case to help boost the relevance of the results.
You can try out a demo of Watson Discovery, that uses a pre-enriched data collection of recent news articles to find out latest trends, sentiments, top stories and entities over last two months.
Watson Discovery + Other Watson APIs
Another powerful way to leverage the discovery service can be to combine it with other Watson services such as Tone Analyzer, Sentiment Analysis or even Speech services. In this tutorial, we will use the discovery service in combination with the Watson Language Translator service to extract relevant information from our private data and present it in different languages.
Our Sample App: Product FAQ Search Engine
Let’s consider an example use case for this tutorial.
XYZ Inc. is a reputed company having a popular product line with an affluent customer base spanning the globe. The company has been making the product for several years and there is a vast amount of documents containing know-how for the product’s features and operations. For the convenience of its customers, XYZ Inc. has created a long FAQ document on its website.
However, with product getting updated periodically with new features, the company is finding it difficult to update the FAQ periodically. For customers, it is time-consuming to traverse through the FAQ to find the correct information and more often than not, they are getting lost. Moreover, with the geographical reach of the company, customers in other countries want the FAQ document in their language.
To address the growing concern of customers, XYZ Inc. tries to search for some automated ways to keep the FAQ page updated. After some in-depth research about the available services to build such an automated tool, they turn to IBM Watson Discovery Service. They also learn about the Watson Language Translator service and find that the capabilities and features of these services can help them satisfy and serve their customers more efficiently.
Code Walkthrough
XYZ Inc. decides to build a Product FAQ Search Engine which will utilize the already existing knowledge base and offer a more straightforward interface to the customers. They also want to utilize the power of connecting different bits of functionalities by connecting different APIs from the Watson services. They decide to utilize the Watson Discovery service along with the Watson Language Translator Service API.
XYZ Inc. wants to create a service called Multilingual FAQBot. This FAQBot can traverse their document collection and provide answers to customer’s queries in their preferred language. Let’s find out how the Multilingual FAQBot can be built and hosted on the IBM Cloud. Let’s have a look at the different components used to build the Multilingual FAQBot and how to set up various services required.
Watson Discovery Service
Watson Discovery Service powers the FAQBot with a simple tooling and provides automated ingestion, natural language processing enrichment, and capabilities to query and extract value from large amounts of data with lesser effort and greater accuracy.
We need to create the discovery service within IBM cloud and upload the required documents to the service. The documents to be uploaded can be PDF, Word, HTML documents or even JSON data. In our case, we will upload the user guide of the company’s product in PDF form.
Watson discovery service will analyze and enrich the database collection with the contents of this user guide. This enriched data can then be queried in natural language to give answers to the Frequently Asked Questions by the customers.
Follow the instructions here to create and configure the Watson Discovery Service.
Watson Language Translator Service
Watson Language Translator service is another powerful service which translates text from one language to another. Here is a quick demo of the translator service. In our Multilingual FAQBot, the translator service is used to translate the output obtained from Watson discovery service to other languages.
Similar to the discovery service, we need to create the Language Translator service on IBM cloud and obtain the credentials required to access the service.
Follow the instructions here to create and configure the Language Translator Service.
PubNub Functions
The queries asked by the customer are published to the PubNub Network. PubNub runs a microservice function via PubNub Functions, and runs the orchestration code for accessing Watson service to provide back the query results.
We need to create a PubNub function hosted within the PubNub network itself to access Watson Discovery and Language Translator service. This function hosts the business logic behind our Multilingual FAQ search engine. PubNub’s network powers real-time delivery of messages between the FAQBot client web-app and the Watson services.
Follow the instructions here to create and configure the PubNub Function.
Web App
The web app is the customer’s point of interaction with the FAQBot service.
The FAQBot web app project utilizes following major SDKs and libraries.
- PubNub Javascript SDK to access PubNub from the webpage of our FAQ bot
- jQuery, Bootstrap and HTML for the front-end webpage which offers an interface to the end user.
To build and run this Multi-Lingual FAQ search engine, you will need to create accounts on IBM Bluemix cloud and PubNub. Visit IBM Cloud and PubNub to create your respective accounts. Generous free tiers are available for both the services.
The README file in the GitHub repository of the project provides instructions to set up and run the FAQbot search engine.
Here is a high-level architecture view for our Multilingual FAQ search engine and a brief about the data flow:
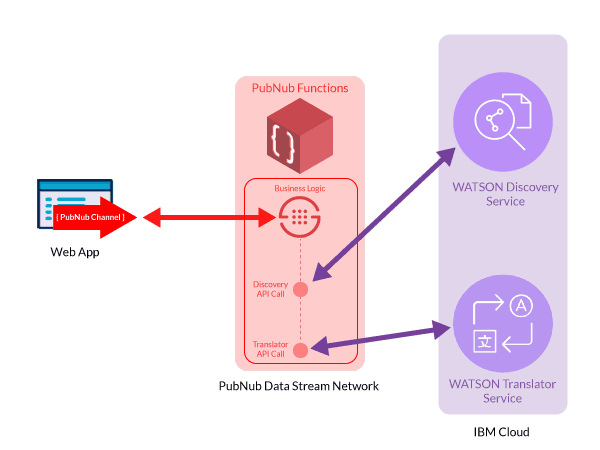
A web page provides interface for the user to query the documents uploaded to Watson Discovery. The webpage also allows the user to select the desired language for answers from Watson. The logic contained in the webpage sends the user queries to PubNub Data Stream Network.
PubNub orchestrates the logic to send the query to Watson Discovery with required authentication and get answers from the data collection. Depending on the target language chosen by the user, the PubNub Function also accesses Watson Translator service and gets answers translated into the desired language. Finally, PubNub Function sends the answers back to the webpage in the user’s desired language.
FAQBot In Action
Once you create the required services on IBM Cloud and PubNub and configure them, you can open the web page UI in your local browser and experience the power of FAQBot.
The demo above shows a local web page with a simple UI to query Discovery holding the collection of the documents you have uploaded. The name of the collection of documents created within Watson Discovery is also shown on the webpage. You can select a target language for the answers.
For this example, we uploaded a user guide for a digital camera to the Discovery service collection. You can ask the Discovery service things related to camera operation. For e.g. you can ask “how to shoot still images” or “how to clean the sensor” and so on. The discovery service with the enriched data provides passage excerpts from the user guide.
Note: Watson Discovery Service is designed to analyze multiple documents within a single collection and provide the best answers from among the documents. In this demo, only one document is uploaded to the service to keep the demo simple.
Conclusion
Traditionally, the knowledge base of any organization is scattered throughout various documents, articles and other forms of information. Traversing through billions of documents and gigabytes of information seems a difficult task to accomplish. Watson Discovery makes it easy to develop apps and systems to maximize the ability to extract meaningful insights from this kind of huge data.
The FAQBot search engine can provide a potential utility to develop a chatbot like application which can act as an automated interaction agent between the customers and an organization’s legacy knowledge base. By uploading multiple documents, blog posts, datasheets, application notes, the FAQbot can be enriched with a vast amount of knowledge about the company’s products and services. The enriched data from these collections can be a powerful tool to improve customer experience by providing them with a quick and easy way to access the required information.
Realtime data streaming, the power of PubNub, helps make the search really fast and seamless to the users. The function modules within PubNub provide a great way to abstract complex functionality of accessing and stacking API operations.
With the intelligence of Watson services and the power of PubNub, the transition from a great idea to a viable product is more fun than ever. We really hope you liked this tutorial and we would love to hear about your journey from an idea to product using Watson services!
