

Private Large Language Models are hosted within an organization’s own computing environment. They offer advantages in terms of managing data privacy compared to the inadvertent use of sensitive data in training public LLMs. However, managing data privacy for LLMs calls for more safeguards than merely running the LLM application within a private infrastructure. Here is a deep dive on the challenges and solutions to fully ensure data protection for private LLMs.
This post was originally published in Skyflow.
Use Case: Managing Data Privacy for LLMs

Problem Statement
Large language models are prone to the use of sensitive or private data, and unlike traditional applications, there is no way to unlearn or use a “delete” button to simply erase the data records from their memory.

Realization Approach
A privacy vault helps harness the full potential of LLMs, by integrating with the existing AI data infrastructure to add an effective layer of data protection. It protects all sensitive data by preventing plaintext information from flowing into LLMs, only revealing sensitive data to authorized users as model outputs are shared with those users.

Solution Space
The technology of privacy vaults fosters ethical and responsible use of AI by streamlining the orchestration and management of sensitive data within a private or local LLM execution environment.
The explosive rise of GPT and other Large Language Models (LLMs) in the field of Generative AI has captured the attention of companies worldwide. Preliminary research shows significant productivity gains for users of generative AI, reminiscent of past technological revolutions. Only six months after general release, as many as 28% of occupations already require some use of ChatGPT.
As the utilization of AI continues to grow, many are raising concerns around privacy and compliance. Recent events have brought these concerns to the forefront of business leaders’ minds, highlighted by Samsung’s ban on ChatGPT due to leaks of its sensitive internal data, Italy’s initial national prohibition (subsequently lifted) on access to ChatGPT, along with Canada’s investigation into ChatGPT and OpenAI following a complaint about unauthorized collection and disclosure of personal information.
While enterprises scramble to evaluate and build on LLMs, potentially leveraging their own customer or internal data to build domain-specific applications, addressing the privacy concerns must be accounted for as enterprises shape their AI strategies.
An emerging trend and recommendation for tackling the privacy challenge for LLMs is to build on private LLM offerings available from major cloud providers or architecture and run a self-hosted LLM. In this article, we take a deep dive into what private LLM is, why you might use it, and most importantly, the limitations.
Understanding the Scope of Managing Data Privacy for LLMs
Whether you’re utilizing tools like ChatGPT or developing your own generative AI system, privacy poses a significant challenge. Products such as OpenAIs GPTs cannot guarantee data privacy, as demonstrated by the recent “poem” prompt injection attack uncovered by Google DeepMind researchers. Additionally, Google’s Gemini’s Privacy Hub states “Please don’t enter confidential information in your conversations or any data you wouldn’t want a reviewer to see or Google to use to improve our products, services, and machine-learning technologies”.
Unlike conventional applications, LLMs have an indelible memory and lack a straightforward mechanism to “unlearn” specific information. There is no practical “delete” button for sensitive data stored within a LLM. In a world where a “right to be forgotten” is central to many privacy tenets, LLM presents some difficult challenges.
Despite the challenges, companies are looking to invest in building domain specific LLMs trained on their own data. For example, Retrieval Augmented Generation (RAG) is becoming the emerging pattern that is used with fast changing data. The source data for RAG may contain customer, employee, or proprietary information.
Sensitive data, like internal company project names, dates of birth, social security numbers, or healthcare information, which can find its way into LLMs through various channels:
- Training Data: LLMs are trained on vast datasets that may contain personally identifiable information (PII). If proper anonymization or redaction measures are not applied, sensitive data enters the model during training and could potentially be exposed later.
- Inference from Prompt Data: LLMs generate text based on user input or prompts. Similar to training data, if the prompt includes sensitive data, it flows into the model and can influence the model’s generated content, potentially exposing this data.
- Inference from User-Provided Files: Beyond simple text prompts, LLM systems allow users to provide documents or other files that might contain sensitive data. These files are processed by LLM-based AI systems such as chatbots, translation tools, or content generators. Similar to prompt data, the sensitive information within the files flows into the model and can potentially be exposed during content generation. This is the common approach used for RAG models.
To help address potential PII leaks to generally available LLMs, enterprises have been encouraged to move to private LLM.
Private LLMs as a Potential Solution for LLM Privacy
Private LLM is a LLM hosted within your own compute environment. This could be a self deployed open source model or an LLM available via VPC from one of the major cloud providers.
There’s several reasons why an organization may choose private LLM over using one of the publicly available LLM services like OpenAI, Cohere, or Anthropic.
- You want full control and customization over the model
- You need more-up-date data in the LLM than currently available in a public model
- You need customer-specific data in your LLM and you’re concerned about sharing the data with a public provider
To see the difference between public and private LLM, let’s consider building a RAG model under both approaches. RAG is one of the most common approaches to improving performance for a LLM for specific tasks and domains. The idea is to pair information retrieval with a set of carefully designed system prompts to anchor LLMs on precise, up-to-date, and pertinent information retrieved from an external knowledge store. Prompting LLMs with this contextual knowledge makes it possible to create domain-specific applications that require a deep and evolving understanding of facts, despite LLM training data remaining static.
In the image below, the front end and orchestration layers are hosted within your cloud environment, while the vector database and the LLM are both remote and managed by third-party services like Pinecone and OpenAI.
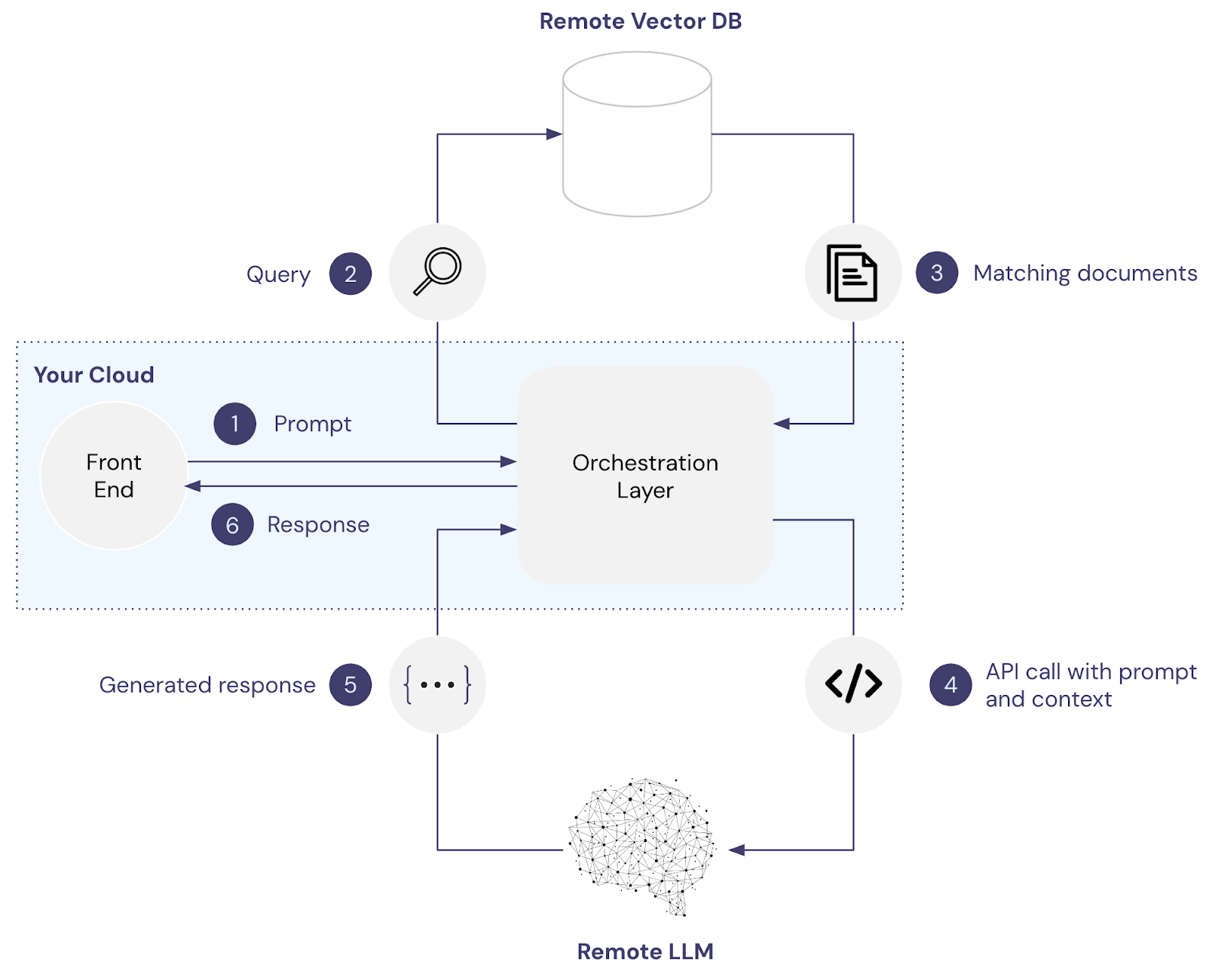
We can modify this architecture by moving both the vector database and LLM internal to our environment as shown below. With this setup, no information shared with the model or vector database is transferred across the Internet.
Note: Although the graphic shows this approach with a self-hosted model, a similar approach is supported by all major cloud providers like Google, Microsoft, AWS, and Snowflake where you connect to a model via VPC, keeping any data shared from flowing across the network.
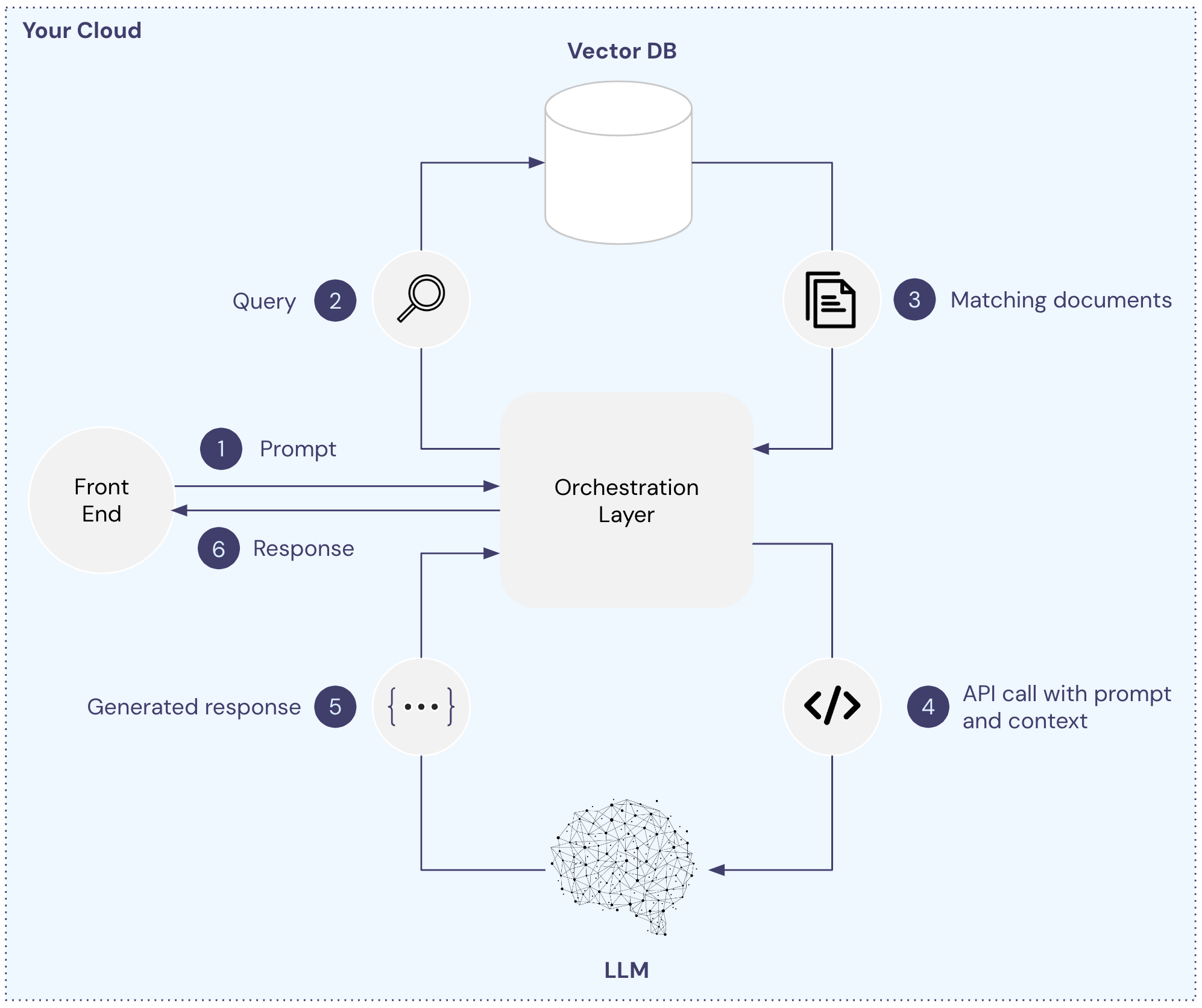
From a privacy point of view, private LLM seems attractive as any sensitive data will only be available within a controlled environment. It doesn’t need to be shared across the Internet with a public LLM service. You can limit access to the LLM to authorized users, there’s no data transfer to third-party services, helping reduce the potential attack surface. However, despite these advantages, there are still many limitations as a solution for security and privacy with LLMs:
- No fine-grained access control
- Lack of enterprise governance
- Difficult to comply with privacy regulations
- Increased maintenance and compute costs
- Difficult to run multiple models
Check out the original post for a detailed coverage on each of the above aspects of managing data privacy for LLMs.
How Skyflow Protects Sensitive Data in Any LLM
Clearly there’s a lot you need to take into account when navigating data privacy and LLMs that private LLMs don’t directly solve. Skyflow Data Privacy Vault is designed to help you harness the full potential of LLMs for diverse use cases while ensuring the utmost security and data privacy.
Skyflow offers comprehensive privacy-preserving solutions that help you keep sensitive data out of LLMs, addressing privacy concerns around inference and LLM training:
- Model Training: Skyflow enables privacy-safe model training by excluding sensitive data from datasets used in the model training process.
- Inference: Skyflow also protects the privacy of sensitive data from being collected by inference from prompts or user-provided files used for RAG.
- Intelligent Guardrails: Ensure responsible and ethical use of language models. Guardrails prevent harmful output, address bias and fairness, and help achieve compliance with policies and regulations.
- Governance and Access Control: Define precise access policies around de-identified data, controlling who sees what, when, and where based on who is providing the prompt. Authorized users receive the data they need, only for the exact amount of time they need it. All access is logged and available for auditing purposes.
- Integrated Compute Environment: Skyflow Data Privacy Vault seamlessly integrates into existing data infrastructure to add an effective layer of data protection. Your Skyflow vault protects all sensitive data by preventing plaintext sensitive data from flowing into LLMs, only revealing sensitive data to authorized users as model outputs are shared with those users.
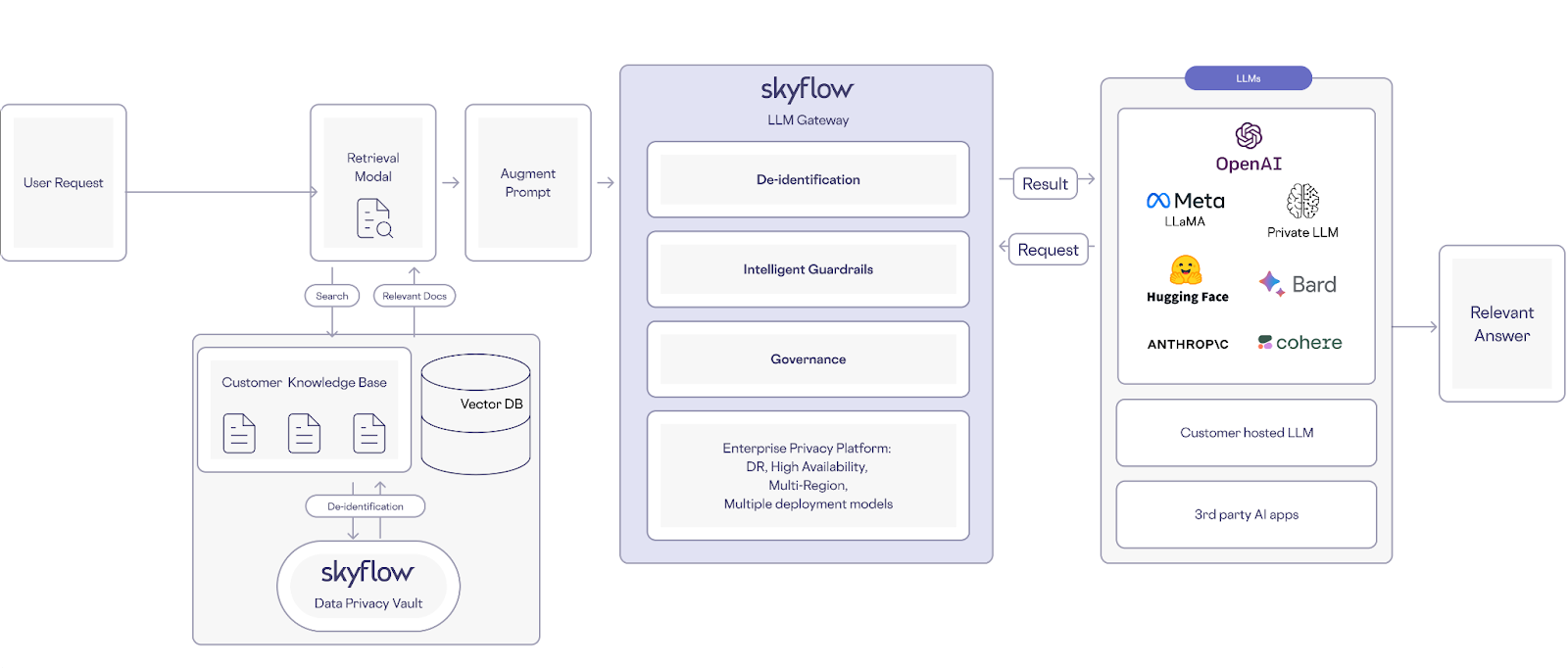
Skyflow de-identifies sensitive data through tokenization or masking and provides a sensitive data dictionary that lets businesses define terms that are sensitive and should not be fed into LLMs. It also supports data privacy compliance requirements, including data residency.
Because sensitive data is swapped with non-exploitable vault tokens (which are distinct from LLM tokens), authorized users get a seamless experience. And because access to detokenize vault-generated tokens is subject to strict zero-trust access controls, unauthorized users won’t get access to sensitive data that are referenced in LLM responses. This means that lower-privileged users can’t access sensitive data, because it isn’t in your LLM, and they don’t have access to redeem the tokens.
This also means that you can have a global LLM without having to worry about data residency as the LLM doesn’t store or have access to regulated data.
This solution delivers the data privacy and data governance that people expect from private LLMs, but that aren’t yet available as integrated features of these platforms.
