

Modulos AutoML allows building state-of-the-art machine learning solutions in a fully automated manner. To further illustrate this, we’ll share a use case where Modulos performed an image classification experiment. Modulos AutoML handles image data, tabular data, as well as a combination of both. This article presents some insights on the low code approach to fast and efficient image classification.
This article was originally published by Modulos.
Imbalanced data sets can result in deceptively good scores (e.g., accuracy) for binary classifications. Adjusting the training objective can therefore improve the score of a model on test data.
For this blog post, we used a publicly available dataset described by the data source as:
divided into two as negative and positive crack images for image classification. Each class has 20000 images with a total of 40000 images with 227 x 227 pixels with RGB channels. The dataset is generated from 458 high-resolution images (4032×3024 pixel) with the method proposed by Zhang et al. (2016). High-resolution images have variance in terms of surface finish and illumination conditions. No data augmentation in terms of random rotation or flipping is applied.
Introduction
Increased manufacturing automation leads to a growing number of produced parts that need to be screened for potential faults. Additionally, detecting faults using different imaging modalities (e.g., cracks in different materials) is becoming crucial in preventive maintenance and reduction of system downtime.
A major issue with detecting faulty parts is the massive amount of data where the vast majority of the components are satisfactory, and only a minute fraction (1:100 to 1:100 000) is faulty, or in our case, cracked. This is a challenge we have to overcome when creating our machine learning model.
Moreover, the faults or cracks are often smaller than the human eye can detect, which further raises the challenge. The so-called microcracks can, when left undetected, have a devastating effect. Imagine the consequences of missing a microcrack in a wing of a plane. As multiple incidents from the past have shown, such a fault can have fatal consequences.
From a technical perspective, the two aforementioned issues – massive amounts of data and microcracks, can be successfully dealt with using artificial intelligence augmented decision support.
However, when setting up such a system from a perspective of a data scientist or a machine learning engineer, we should keep in mind these two possible threats:
- Highly imbalanced data may result in overly optimistic scores (e.g., accuracy) when the wrong training and evaluation objectives are chosen.
- False negatives can have catastrophic consequences, whereas false positives are often neglected.
Data Preparation and Model Training
We first downloaded the images from the source and manually resized them to 128×128 pixels. Manual resizing was used to overcome the limitations of the identity transformation feature extractor implemented in Modulos AutoML v.0.3.5.
While it may be counterintuitive, for this experiment, the positive class is defined as the class containing images with a crack, while the negative class is the one containing images without a crack.
We randomly selected 19 478 negative (no crack) and 121 positive (crack) from all images to make up the training dataset, resulting in a 160:1 imbalance between the two classes. We applied no other data manipulation, preprocessing, or augmentation.
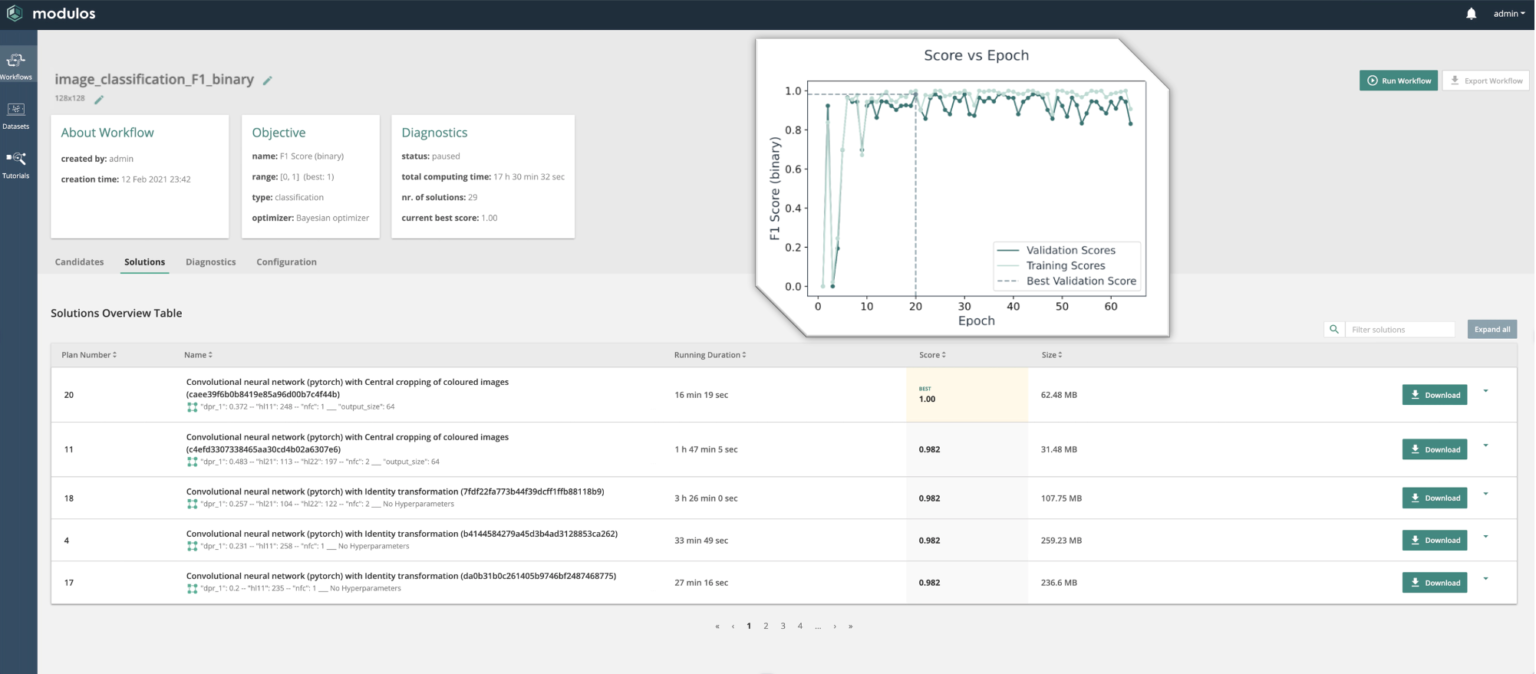
The resulting .tar archive of 93MB was uploaded to Modulos AutoML v.0.3.5 running on an Amazon AWS instance with 1 GPU. We set AutoML to use the Bayesian optimization strategy, with the F1 binary as the objective function. AutoML splits the data into an 80% training data set, and a 20% validation data set used to evaluate each machine learning solution.
Definitions:
- True Positive (TP): Correctly predicting a class 1 (we predicted “crack,” and it’s “crack”),
- True Negative (TN): Correctly predicting the other label (we predicted “no crack,” and it’s “no crack”),
- False Positive (FP): Falsely predicting a label (we predicted “crack,” but it’s “no crack”),
- False Negative (FN): Missing an incoming label (we predicted “no crack,” but it’s “crack”).
Results and Discussion
After 17 hours of training we manually paused the workflow to test the model performance on hold-out test data. For this test we used solution plan number 18. Investigation of solutions number 20 and 11 showed that “central cropping” as a feature engineering step removed cracks that were not centered on the image, producing many false negatives. As the same feature engineering is applied to the test data set, we only spotted this behavior by manually investigating the results. This example highlights the need for domain knowledge when building ML solutions.
The batch client (Jupyter Notebook) provided with each Modulos AutoML solution generated predictions. In a next step, we evaluated these predictions vs the known labels from the hold-out test data.
We achieved an F1 score binary of 0.9206 (validation score 0.982), indicating that our model generalizes well for the unseen test data.
Further, as shown in Figure 2, the Accuracy (0.9956) is very high, despite 4 out of 33 true samples being classified incorrectly. As mentioned above, this is a result of the class imbalance of the data set. Using F1 binary during optimization helped us avoid choosing an inadequate model optimized for accuracy.

As stated in the introduction, in most similar real-life use cases, we would mainly be concerned about the False Negative Rate (0.1212) as it is often less costly to inspect a satisfactory part that is classified as faulty, than missing a faulty part.
Of course, there are other situations where both classes are equally important and all four values (TP, FP, TN, FN) matter. For such cases, the Matthews Correlation Coefficient (MCC) can be a valuable additional evaluation criterion when dealing with imbalanced data sets for binary classifications. The MCC takes all four values (TP, FP, TN, FN) into account and ranges from -1 to +1. An MCC close to 1 means that both classes are predicted well, while an MCC close to -1 means that the classes cannot be predicted using the model, and a score close to 0 means that the classifier behaves like a fair-coin.
Key Learnings and Tips
- First off all, it’s important to always keep test data separated from the training data when testing your model.
- Choosing the correct objective is essential to generating machine learning models that generalize well for unseen test data.
- Keep in mind that accuracy can be a misleading score when dealing with highly imbalanced data. If FNs or FPs are less critical, one can select precision, recall, or F1 as a better alternative to accuracy. The Matthews Correlation Coefficient (MCC) is a valuable alternative evaluation metric when all four values from the confusion matrix matter.
- Additionally, when dealing with imbalanced data sets, many techniques (e.g., random oversampling, SMOTE) for building better models are at your disposal. However, one should always carefully evaluate models trained on resampled data against the original distribution. Therefore, it is advisable to resample after the train/test split to keep the test data. Lastly, always report scores on the hold-out test data not used for training or evaluation.
