

This post is the follow up to my previous post in which I presented a real-time recommendation engine project around predicting duration of travel. In that post, I explored the factors affecting travel duration and looked at how, with the help of historical data, you can build an algorithm for predicting travel duration for a given route. Now, I will conclude the project by building an application that can help users plan a trip by providing real-time travel recommendations based on current traffic and weather conditions.
Project source
The complete source code for this application is available on GitHub.
The source code is partitioned under four directories:
ttoApp— source code for TTO mobile app based on Cordova and AndroidttoBackground— source code for background scriptttoServer— source code for the application serverttoTest— source code for the test script to induce real-time alerts
Refer to the README file for complete step-by-step instructions for deploying the application on IBM Bluemix and operating the TTO mobile app.
Before you deploy your application, be sure to sign up for IBM Bluemix and PubNub accounts. Visit the IBM Bluemix signup page and the PubNub add-on page to create your accounts. Both services offer free-tier accounts that let you play around with their offerings.
You will also need a MongoDB database instance for storing the historical traffic data. We use mLabMongoDB hosting service for this project.
Recap from Part 1
This application tries to answer the age-old question every traveler asks before starting their journey: “When should I start?” The objective of the TTO Recommendation Engine is not only to provide certain options to help answer this question, but also to provide real-time advisories about traffic based on the impending factors.
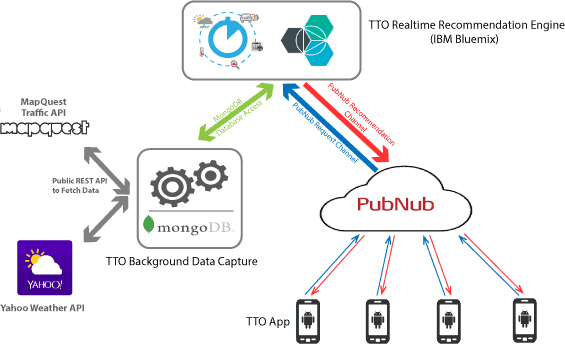
The process for building this recommendation engine can be broken down into two steps, which I presented earlier:
- Derive predictions for travel duration for a period in the future
- Generate recommendations based on those predictions, as determined by the time requested by the user
I already showed you how to capture historical data for factors that affect traffic, and how to used that data to derive predictions for travel duration. But there is more work to be done than merely predicting travel duration. Let’s dive in.
Deriving predictions
Using the k-Nearest Neighbors algorithm (KNN, for short), we can predict the travel duration for a time in the future, based on the data available from the past. From the user’s point of view, this time in the future represents the departure time. So given a departure time for the travel along a given route, the algorithm can predict the approximate travel duration for that route.
Since the algorithm can take considerable time to perform each prediction, it makes more sense to build this prediction for a time period in the future.
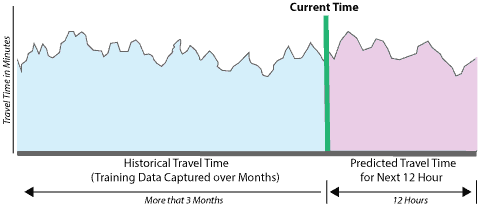
So the purpose of the background process (TTO Background Data Capture) is not only to collect and maintain historical data, but also to maintain a 12-hour advance prediction from the current time. This means that at any point in time, the application has access to 12 hours of advance predictions of travel duration for all three of the routes that we have considered for this project.
Here is what the process flow looks like:

In order to keep the data manageable and reduce the workload on our KNN algorithm, the data capture is done at 10-minute intervals, so the advance predictions are available every 10 minutes. This means that if the current time is 10:30 A.M., then the 12-hour advance prediction is available for 10:30 A.M. to 10:30 P.M. every 10 minutes, starting at 10:30 A.M., 10:40 A.M., 10:50 A.M., and so on, until 10:30 P.M.
Generating recommendations
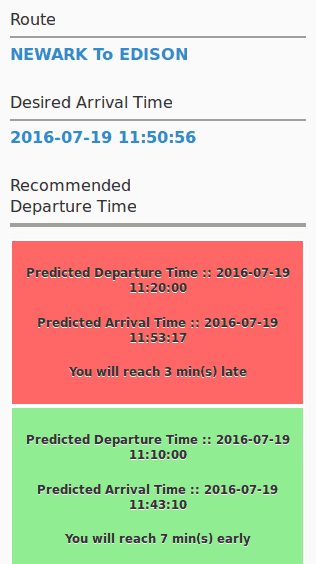
Recommendations are always generated for a route with respect to an arrival time, since the arrival time is always determined by the user. We’ll call this the Desired Arrival Time (DAT). So for a given DAT, a recommendation consists of the following data points:
- Predicted Departure Time (PDT)
- Predicted Arrival Time (PAT)
- Recommendation Type
- Desired Arrival Time Delta (DAT▲)
And here’s how a recommendation is presented to the user:
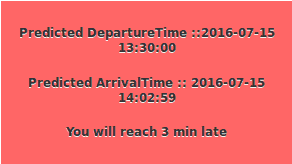
The Predicted Departure Time and Predicted Arrival Time values are self explanatory. The final message, “You will reach 3 min late,” contains the Recommendation Type and DAT▲ value. The value 3 (minutes) represents the delta between the user-selected DAT and the Predicted Arrival time, and “late” represents the Recommendation Type.
Recommendation Type values can be either “Early,” “Late,” or “OnTime,” and together with DAT▲, it provides a reasonable guideline for helping the user arrive at a pragmatic decision.
Recommendation generation algorithm
To provide the user with a balanced option, the system should provide recommendation values of either “Early” or “Late.” The only exception is “OnTime”; if an “OnTime” recommendation is available, then only that recommendation will be presented to the user.
Let’s look at how the recommendation generation algorithm works. There are three input parameters for the algorithm:
- Selected Route — one of the predefined routes chosen by the user
- Desired Arrival Time (DAT) — the time when the user wishes to reach his or her destination
- Theoretical Travel Duration (TTD) — the time required to travel from source to destination for the selected route under ideal conditions with no traffic; this parameter is also available from the MapQuest API
Here is the flowchart for this algorithm:
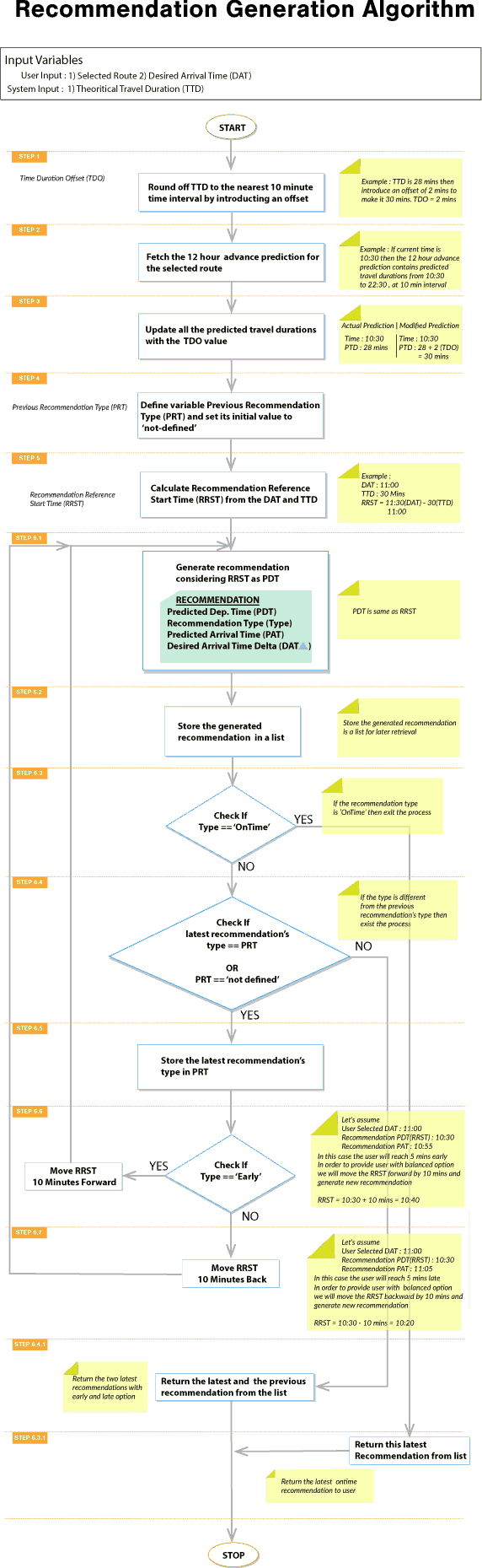
Note: The Travel Duration Offset is introduced here to compensate for the 10-minute sampling duration that’s used in TTO Background Data Capture. If the data were sampled every second (which would be typical in a real-world application), then this parameter and the associated steps in the flowchart would not be required.
Refer to the ttoServer source file to see how this flowchart unfolds as Python source code. The comments in the source code point you to the corresponding steps in the flowchart.
The algorithm will output either:
- a single “OnTime” recommendation, or
- One “Early” and one “Late” recommendation with the smallest DAT▲ value.
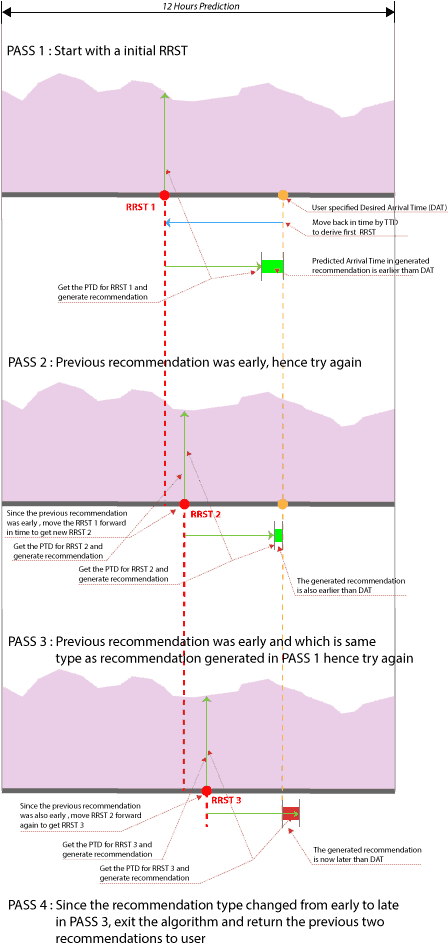
To arrive at suitable output, the algorithm will execute through several passes. At each pass, it will shift the Recommendation Reference Start Time (RRST) to generate a recommendation.
The following illustration depicts how the RRST is initially derived and then shifted through multiple execution passes to get an “Early” or “Late” recommendation:
Application process flow
The process flow for the ttoApp mobile app is as follows:
- The user launches the TTO app, selects the travel route and the desired arrival time, and then clicks “Submit.”
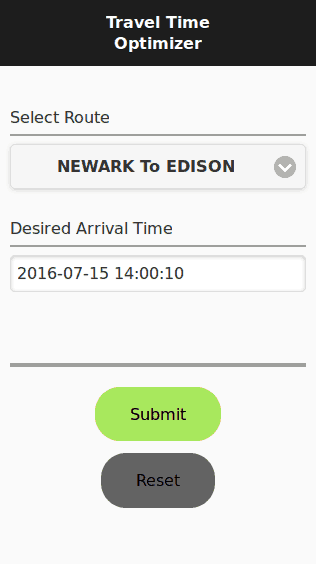
- The TTO app sends the request to the TTO Recommendation Engine, which is hosted under
ttoServer. The TTO Recommendation Engine runs the algorithm and returns recommendations.
- The user then selects one of the presented recommendations, and the app starts a countdown to the start of the journey (per the Predicted Departure Time in the selected recommendation). This is the pre-journey phase.
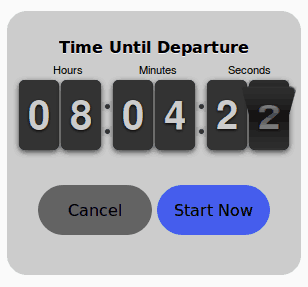
During this time, the TTO Recommendation Engine may send real-time recommendation alerts if there is a change in weather conditions that alters the previous prediction, or if there is an incident reported along the route.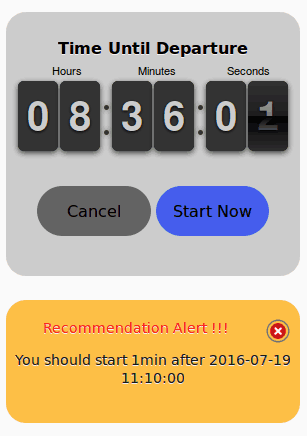
- When the countdown concludes, or the users taps “Start Now,” the TTO app enters the journey tracking phase. During this time, the TTO Recommendation Engine sends real-time recommendation alerts only if there is an incident reported along the route.
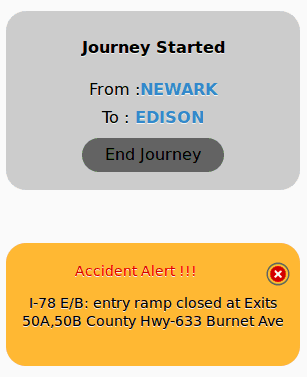
Finally, when the user selects “End Journey,” the app closes its session with the server.
Note that in this application, the real-time recommendation alerts are not exactly real time because the TTO Background Data Capture process samples the factors that affect traffic every 10 minutes, so the alerts may be delayed by a maximum of 10 minutes. However, in a real-world application where samples are taken every few seconds, the alerts can be sent in near-real-time speeds.
Client-server message exchange
Message exchange between client and server is facilitated through the PubNub channels. All requests from the app are sent through the PubNub request channel (marked in blue), which is a common channel for all app instances. Responses are sent through the PubNub recommendation channel (marked in red), which is a private channel that is initiated by the server with every app instance.
Here is how the TTO app interacts with the TTO Server/Recommendation Engine:
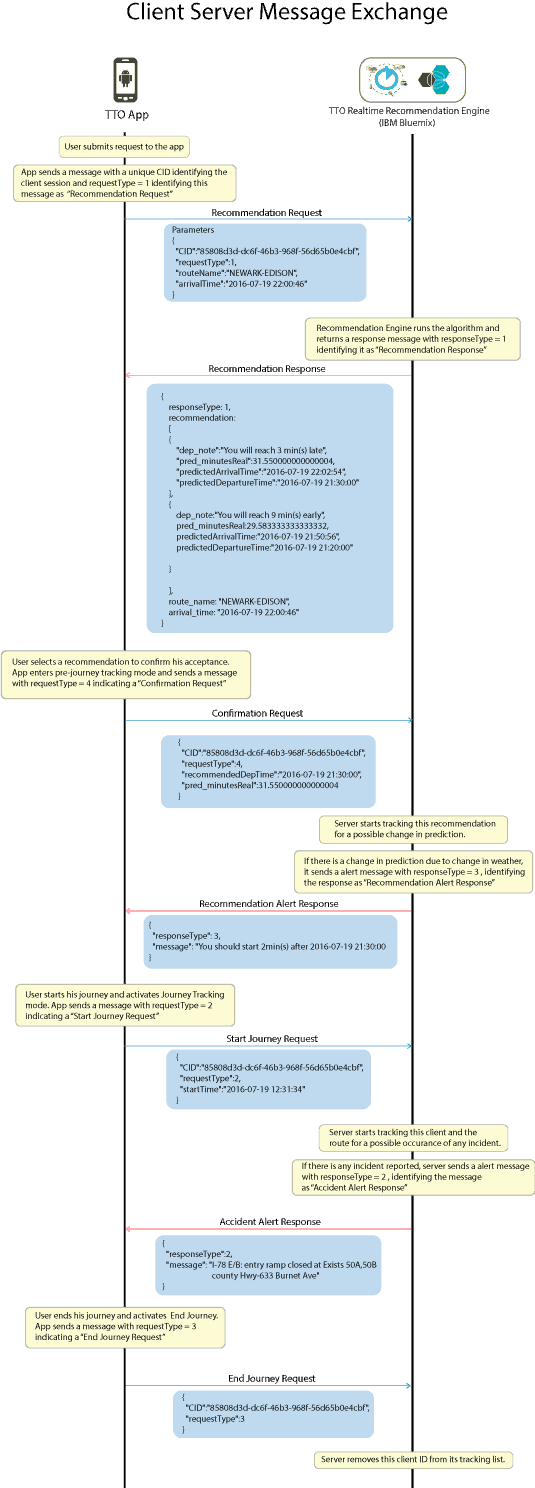
Conclusion
It has taken us more time than usual to build this application thanks to the overwhelming amount of data and the research involved, but it is always fun to work with live data. Deriving meaningful and practical insights from live data can be priceless, and all of this is possible thanks to advances in cognitive computing that have been spearheaded by the awesome folks at IBM. With the addition of PubNub, it is now easy to build applications that can spread these insights to thousands of users in real time, and then it feels like taming the data at your will. With the tsunami of data that overwhelms us today, such capabilities will be the hallmark of all future data-driven applications.
