

GraphQL is an open-source data query and manipulation language for APIs, and a runtime for fulfilling queries with existing data. Data mesh is a new approach based on a modern, distributed architecture for analytical data management. It enables end users to easily access and query data where it lives without first transporting it to a data lake or data warehouse. This article discusses how to ensure developer productivity in the age of exploding data using GraphQL and Data Mesh.
This article was originally published in Hasura.
GraphQL has now been around for over 5 years, and has been adopted across companies as varied as GitHub, Airbnb, New York Times, Philips, government organisations and some of today’s fastest growing startups. GraphQL is an API specification created at Facebook that took the developer world by storm. The core of GraphQL’s popularity was the developer experience and productivity it provided to the frontend/full stack developer, who no longer needed to wait on a backend developer to build an API for them. The ability to dynamically fetch whatever data is required is a productivity dream that GraphQL seemed to be in the best place to enable.
However the realities of enabling GraphQL inside of an organization are multifold. GraphQL promises one single API for all your application development needs. For this to indeed be true, the GraphQL API needs to be able to fetch data across multiple domains. This opens up further architectural challenges to account for performance, security and scalability as well as organisational challenges of how teams should be architected – where is authorization handled, who is responsible for performance, how is the GraphQL API maintained, how does the workflow change for each microservice author, and so on.
Meanwhile, in an adjacent data universe of analytical / static data, the idea of a data mesh was born.
What is a Data Mesh?
The idea of data mesh was introduced by Zhamak Dehghani (Director of Emerging Technologies, Thoughtworks) in 2019. Zhamak describes Data Mesh as “an architectural paradigm that unlocks analytical data at scale; rapidly unlocking access to an ever-growing number of distributed domain data sets, for a proliferation of consumption scenarios such as machine learning, analytics or data intensive applications across the organization. Data mesh addresses the common failure modes of the traditional centralized data lake or data platform architecture, with a shift from the centralized paradigm of a lake, or its predecessor, the data warehouse. Data mesh shifts to a paradigm that draws from modern distributed architecture: considering domains as the first-class concern, applying platform thinking to create a self-serve data infrastructure, treating data as a product and implementing open standardization to enable an ecosystem of interoperable distributed data products.”
Can the Data Mesh Concept be Applied to Operational Data?
Operational data is becoming increasingly fragmented – data is stored across multiple databases depending on the nature of the data. Relational and transactional data could be in Postgres/MySQL (and increasingly in distributed and scale-out flavours of these databases!), search data or materialized data could be in a document stores like Mongo & Elastic, and workload specific data like timeseries could use another type of databases. In addition to this, data that’s required to be accessed by applications could come from 3rd party SaaS services and CMSes. Although the data is spread across these sources, they’re still potentially inter-related and fulfil the goals of a domain.
Similar to what the data mesh tries to address with analytical data, distributed operational & transactional data can also be made self-serve for application developers by creating a single semantically unified API so that frontend / full stack developers can access any data fast to build applications and experiences for their users.
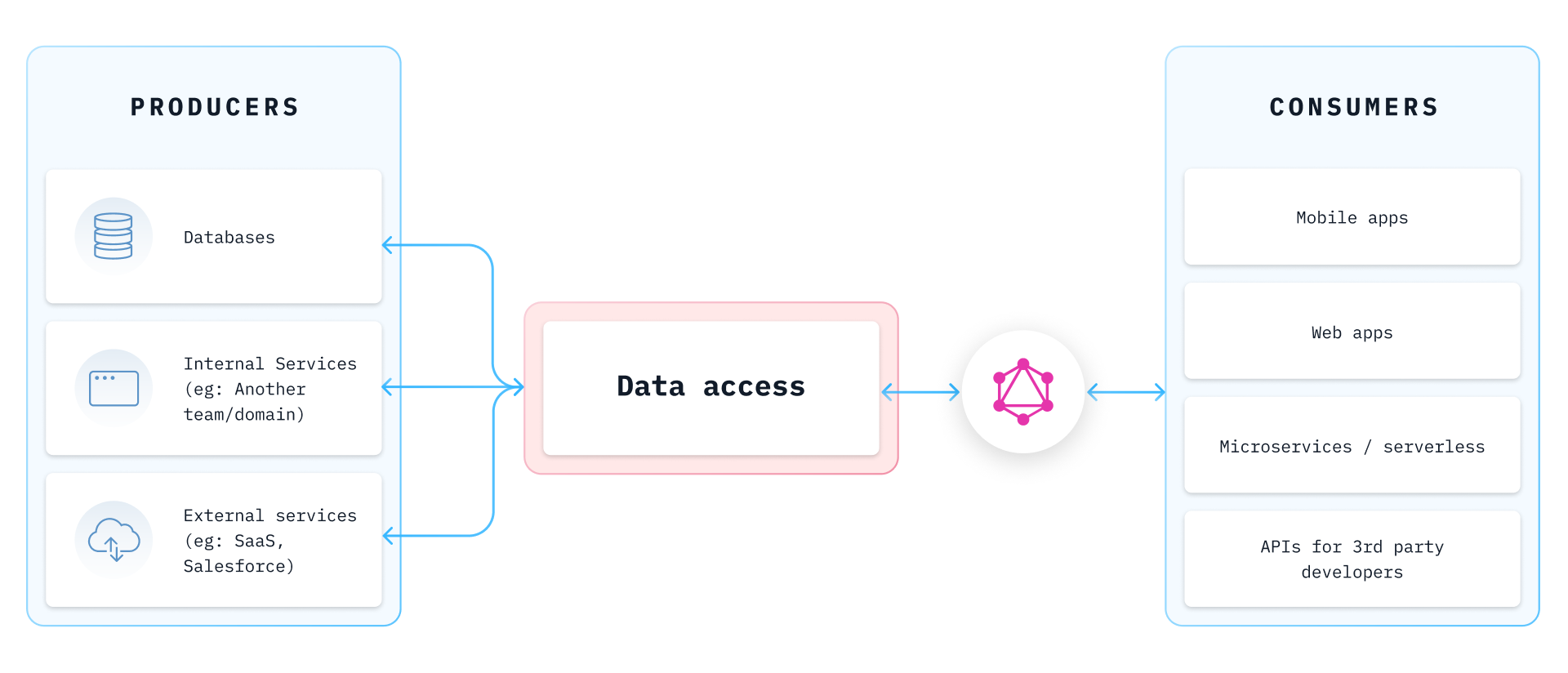
The promise of GraphQL and the architectural concept of the data mesh seem to be perfectly suited to solve the application development challenges of the modern enterprise – with an extreme focus on developer productivity and enablement of the application developer; both of which are themes very dear to our hearts at Hasura!
