

Answering questions like “is our data anomalous?” and “how has this metric trended over time?” requires historical knowledge of our data over time. Until storing complete historical snapshots of our data becomes feasible, we’re left with storing approximations. How much data do we need to reconstruct a useful picture of our data? That’s the question we attempt to answer in this article. The groupings of questions we need to answer in order to describe our data are the “pillars” that underlie data observability.
This article was originally published by Metaplane.

Why do We Need Yet Another Pillar of X Post?
Software Observability is built on top of the three pillars of metrics, traces, and logs. Metrics are numeric values that describe components of a software system over time, like the CPU utilization of their microservices, the response time of an API endpoint, or the size of a cache in a database. Traces describe dependencies between pieces of infrastructure, for example the lifecycle of an application request from an API endpoint to a server to a database. Logs are the finest grained piece of information describing both the state of a piece of infrastructure and its interaction with the external world. With these three pillars in mind, software and devops engineers can gain increased visibility into their infrastructure throughout time.
The purpose of the three pillars is to describe the three categories of information that can be used to reconstruct, in as much detail as is relevant to a use case, the state of software infrastructure. That is closely tied to why the term “observability” was borrowed from control theory, where observability is defined as a “measure of how well internal states of a system can be inferred from knowledge of its external outputs.” The pillars, together, should let users infer knowledge of the internal state of a system at any point in the past.
Data Observability draws inspiration from Software Observability, though there are important differences like the lineage between pieces of data and the components of a data system. Because of those differences, the three pillars of Software Observability don’t quite address the needs of data teams, whether they’re DataOps, data engineering, data science, or analytics engineering teams. The overarching similarity, though is the goal of increasing visibility into their data systems over time.
How Can We Derive the Four Pillars?
In that spirit, we ask: what can we know about data to derive its state at any point in time? We add two additional constraints: we want to minimize the number of pillars to be maximally concise, while making sure that they’re orthogonal to maximize information value of each.
We look at a concept of thermodynamics: the intensive and extensive properties of materials. Intensive properties do not depend on the size of material. For example, the temperature, density, pressure, and viscosity of a material does not depend on how much material there is. One cup of water can have the same temperature as an entire ocean.
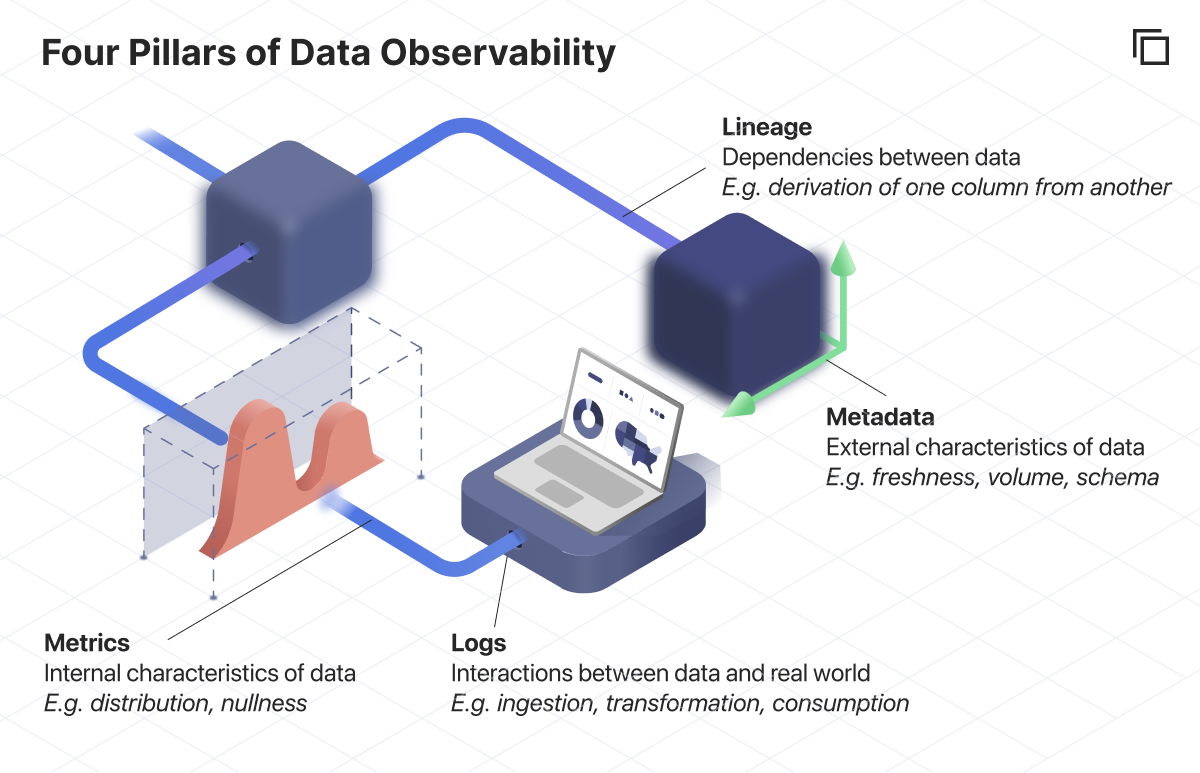
Metrics: Internal Characteristics of the Data
In the world of data, the analogy to intensive properties are properties of the data itself. If the data is numeric, properties include summary statistics about the distribution like the mean, standard deviation, and skewness. If the data is categorical, summary statistics of the distribution can include the number of groups, the uniqueness. Across all types of data, metrics like completeness, whether it includes sensitive information, and accuracy can be computed to describe the data itself. These are all different data quality metrics that describe some aspect that summarizes the underlying data, whether they’re calculated for data tables at rest in a warehouse or data in transit in data pipelines.
Metadata: External Characteristics About the Data
Extensive properties, in contrast, are independent of the material itself, like mass and volume and heat capacity. You can have a pound or a liter of both water and gold. Note that the analogy isn’t exact, because in thermodynamics, extensive properties depend on the amount of material, which freshness and structure do not depend on.
Metadata is frequently defined as “data about data,” but we’d add that metadata is “data about data that is independent of the data itself.” Direct analogies to the world of data include properties like data volume (number of rows), the structure of data (schema), and the timeliness of data (freshness).
While the volume, schema, and freshness of data have an impact on the internal metrics, they can be scaled independently while preserving the statistical characteristics. Conversely, the internal characteristics of data can change without impacting the volume, schema, or freshness. Together with metrics, metadata can be used to identify data quality issues.
Lineage: Dependencies Between Data
Using metrics and metadata, we can describe a single dataset with as much fidelity as we desire. However, datasets in the real world often do not exist in isolation, landing in a data warehouse with no relationship to each other.
We can draw another analogy from the physical sciences, where systems can be modeled within themselves, but our understanding can be enriched by modeling interactions. For example, thermodynamic systems have smaller components with internal interactions, and also have interactions with the external environment.
Within the data world, the primary internal interaction is the derivation of one dataset from another. Datasets are derived from upstream data, and can be used to derive downstream data. These bidirectional dependencies are referred to as the lineage of data (also called the provenance), and range in level of abstraction from lineage between entire systems (this warehouse depends on those sources), between tables, between columns in tables, and between values in columns.
Logs: Interactions Between Data and the Real World
With metrics describing the internal state of data, metadata describing its external stage, and lineage describing dependencies between pieces of data, we’re only missing one piece: how that data interacts with the external world. We break these interactions into machine-machine interactions and machine-human interactions.
Machine-machine interactions with data include movement, like when data is being replicated from data sources like transactional databases or external providers to an analytical warehouse by an ELT tool. Interactions also include transformations, for example when a dbt job transforms source tables into derived tables. Logs also document attributes of these interactions, for example the amount of time that a replication or transformation takes, or the timestamp of that activity.
Crucially, logs capture machine-human interactions between data and people, like data engineering teams creating new models, stakeholders consuming dashboards for decision making, or data scientists creating machine learning models. These machine-human interactions contribute an understanding of who is responsible for data and how data is used.
Putting it All Together
With metrics describing the internal properties of data, metadata describing the external properties, lineage describing the dependencies, and logs describing the interactions, we have four levers that we can pull in order to fully describe the state of our data at any point in time.
Without any one of the pillars, our ability to reconstruct the state of data is incomplete. Without metrics, we do not have knowledge about the internal properties of the data itself, making alerting based on real-time anomaly detection on metrics impossible. If we only had metadata, we would know the shape, structure, and timing of data, but not necessarily whether we had bad data.
Without metadata, we do not know the structure, structure, or timing of data, making use cases like schema change detection or satisfying Service Level Agreements (SLAs) by tracking outages impossible. These use cases are critical to improve data reliability and decrease data downtime. If we only had metrics, we would know whether the data is correct, but not necessarily if it was refreshed in an appropriate amount of time.
Without lineage, we do not know how different pieces of data depend on each other, making it difficult to analyze upstream root cause and downstream impact of data quality issues. If we only had metrics and metadata, we have a holistic view of the health of data, but an incomplete picture of how issues are related.
Without logs, we do not know how external systems like ELT and transformation tools impact our data and how external users are impacted by our data. With only data lineage, we know how data is related, but not necessarily how important those relationships are (does anyone use this data?) or who is responsible for upstream changes.
Putting the Pillars to Work
Getting started with building up these pillars is a project of not letting the perfect get in the way of good. Most data teams in 2021 have little information about their systems, so the first step is to just get started. To start collecting metrics, you can start by identifying the most important tables and metrics, periodically query properties like the `nullness`, `mean` and `standard deviation` of those metrics. Metadata is often provided out of the box by your data warehouse, with warehouses like Snowflake and Google BigQuery providing snapshots of the row count, schema, and last update time of tables in `INFORMATION_SCHEMA`. You can begin by storing that metadata into a separate table.
Lineage and logs are a bit more challenging. Inferring the lineage between tables and columns is a difficult task, but there are some open source libraries that provide a starting point. If you use a transformation tool like dbt or Prefect, you’re in luck, and can start ingesting the metadata generated by those systems. Storing and parsing logs is highly dependent on the tools in your data stack, though often your ELT and BI tools will provide an API for accessing those logs, and your warehouse will likely store query history.
If you don’t have the bandwidth to build systems that collect metrics, metadata, lineage, and logs of your data assets, that’s where data observability platforms come into the picture. The is a lively ecosystem of commercial and open source tools that automate the collection of this information, synthesize it into a usable form, and integrate with the tools you already use. Metaplane is one option to consider if you want to start using a tool out-of-the-box within 30 minutes.
Summary
- Until it’s feasible to store snapshots of data over time, we rely on storing approximations of our data, ala lossy compression
- Four categories of characteristics about our data form the four pillars of Data Observability
- The Metrics and Metadata pillars describe the internal characteristics of our data itself and its external characteristics
- The Lineage and Logs pillars describe internal dependencies within our data and its interactions with the external world
- Without any of our these four pillars, we’re left with an incomplete picture of our data at a given point in time
